访问 Spark
1.从spark与hadoop安装目录中取下列jar文件(请根据实际所用版本取对应的jar文件),放到产品外部库文件夹中;Spark外部库文件路径为:安装目录\ esProc\extlib\ SparkCli;润乾核心jar为sparkcli.jar。
antlr-runtime-3.4.jar
antlr4-runtime-4.5.jar
chill_2.11-0.8.0.jar
commons-cli-1.2.jar
commons-codec-1.4.jar
commons-compiler-2.7.6.jar
commons-configuration-1.6.jar
commons-lang-2.6.jar
commons-logging-1.1.3.jar
hadoop-auth-2.6.5.jar
hadoop-common-2.6.5.jar
hadoop-hdfs-2.6.5.jar
hadoop-mapreduce-client-core-2.6.5.jar
hadoop-mapreduce-client-jobclient-2.6.5.jar
hive-common-2.1.1.jar
hive-exec-2.1.1.jar
jackson-annotations-2.6.5.jar
jackson-core-2.6.5.jar
jackson-databind-2.6.5.jar
jackson-module-paranamer-2.6.5.jar
jackson-module-scala_2.11-2.6.5.jar
janino-2.7.8.jar
javax.ws.rs-api-2.0.1.jar
jersey-container-servlet-core-2.22.2.jar
jersey-server-2.22.2.jar
json4s-ast_2.11-3.2.11.jar
kryo-shaded-3.0.3.jar
log4j-1.2.17.jar
lz4-1.3.0.jar
metrics-json-3.1.2.jar
netty-all-4.0.29.Final.jar
paranamer-2.3.jar
scala-library.jar
scala-reflect-2.11.8.jar
scala-xml_2.11-1.0.2.jar
spark-catalyst_2.11-2.0.2.jar
spark-core_2.11-2.0.2.jar
spark-hive_2.11-2.0.2.jar
spark-launcher_2.11-2.0.2.jar
spark-network-common_2.11-2.0.2.jar
spark-network-shuffle_2.11-2.0.2.jar
spark-sql_2.11-2.0.2.jar
spark-unsafe_2.11-2.0.2.jar
xbean-asm5-shaded-4.4.jar
hive-cli-2.1.1.jar
hive-jdbc-2.1.1-standalone.jar
hive-metastore-1.2.1.spark2.jar
htrace-core-3.0.4.jar
jcl-over-slf4j-1.7.16.jar
2.从网上下载以下四个文件,放到:安装目录\bin下
hadoop.dll
hadoop.lib
libwinutils.lib
winutils.exe
注意:windows环境下需要以上四个文件,Linux环境中不需要, 并且winutils.exe区分x86与x64。
3.SparkCli要求java环境为jre1.7及以上版本,集算器自带的版本为jre1.6,所以需要用户自己安装高版本jre。并在:安装目录\ esProc\bin\config.txt文件中配置java_home。如果用户在安装集算器时,已选择1.7及以上版本的jdk,则此步可以省略。
4.当占用内存比较大时,用户可自己调整内存,目前windows下有两种方式,使用exe启动时在config.txt里修改内存,使用bat启动时是在bat文件中修改内存。Linux下是在sh文件中修改内存大小。
在windows下修改config.txt方法如下:
java_home=C:\ProgramFiles\Java\jdk1.7.0_11;esproc_port=48773;jvm_args=-Xms256m -XX:PermSize=256M -XX:MaxPermSize=512M -Xmx9783m -Duser.language=zh
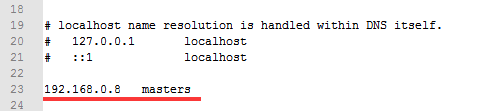
5.在集算器所在机器中,找到hosts文件,添加spark所在机器的IP地址与主机名称,例如spark所在机器IP为192.168.0.8,主机名为:masters,那么如下图设置:
6.访问Spark可使用的外部库函数有spark_client()、spark_query()、spark_cursor()、spark_close()。函数用法请参考【帮助】-【函数参考】