- 数据类型
- 操作符
- 数学
- 字符串
- 日期时间
- 序列
- 序表
- 循环函数
- 关联运算
- 文件
- 数据库
- 游标
- 程序语句
- 系统与接口
- 集群
- 图形
- 财务
- 外部库
- 组表
-
Function
- #c
- $(db)sql;…
- ${macroExp}
- =expression
- >statement
- [a:b]
- @
- A()
- A. (x)
- [a1,…,an]
- abs()
- acos()
- acosh()
- age()
- align()
- ali_client()
- ali_close()
- ali_query()
- and()
- append()
- array()
- asc()
- asin()
- asinh()
- atan()
- atanh()
- attach()
- avg()
- base64 ()
- between()
- bits()
- bool()
- break {a}
- C
- Cr()
- calc()
- call()
- call path/dfx( … )
- callx()
- cand()
- canvas()
- case()
- ceil()
- ch.()
- channel()
- char()
- clear()
- clipboard ()
- close()
- cmp()
- cor ()
- combin()
- commit()
- concat()
- conj()
- conjx()
- connect()
- contain()
- cos()
- cosh()
- count()
- create()
- cs.( )
- cum()
- cursor()
- date()
- datetime()
- day()
- days()
- decimal()
- delete()
- deq()
- derive()
- dfx ( …)
- diff()
- directory()
- dup()
- elapse()
- end s
- enum()
- env()
- eq()
- error()
- eval()
- es_close ()
- es_delete()
- es_head()
- es_open()
- es_get()
- es_post()
- es_put()
- execute()
- exists()
- exp()
- export()
- f@o(…)
- Faccrint()
- Faccrintm()
- fact()
- false
- Fcoupcd()
- Fcoups()
- Fdb()
- Fddb()
- Fdisc()
- Fduration()
- fetch()
- field()
- file()
- filename()
- fill()
- find()
- Fintrate()
- Firr()
- float()
- floor()
- Fmirr()
- fname()
- fno()
- Fnper()
- Fnpv()
- for
- fork
- format()
- Fpmt()
- Fprice()
- Frate()
- Freceived()
- Fsln()
- Fsyd()
- ftp_cd()
- ftp_client()
- ftp_close()
- ftp_get()
- ftp_mkdir()
- ftp_put()
- func()
- Fv()
- Fvdb()
- Fyield()
- gcd()
- goto C
- group()
- groupi()
- groupn()
- groups()
- groupx()
- hash ()
- hbase_close()
- hbase_cmp()
- hbase_filter()
- hbase_filterlist()
- hbase_get()
- hbase_open()
- hbase_scan()
- hdfsfile()
- hdfs_client()
- hdfs_close()
- hdfs_dir()
- hdfs_file()
- hive_client()
- hive_close()
- hive_cursor()
- hive_execute ()
- hive_query()
- hosts()
- hour()
- httpfile()
- icursor()
- icount()
- id()
- if
- if()
- ifa()
- ifdate()
- ifn()
- ifnumber()
- ifr()
- ifstring()
- ift()
- iftime()
- ifv()
- ifx_close()
- ifx_conn()
- ifx_cursor()
- ifx_listfrag()
- ifx_savefrag()
- ifx_setfrag()
- ifx_takefrag()
- import()
- index()
- inf()
- insert()
- int()
- interval()
- inv()
- invoke()
- isalpha()
- isdigit()
- isect()
- iselect()
- islower()
- isolate()
- isupper()
- iterate()
- join()
- joinx()
- json()
- k()
- k{}
- kafka_close()
- kafka_commit()
- kafka_poll()
- kafka_subscribe()
- key()
- keys()
- lcm()
- left()
- len()
- lg()
- like()
- ln()
- lock()
- long()
- lower()
- m()
- max()
- maxp()
- mcursor()
- md5()
- median()
- memory()
- merge()
- mergex()
- mid()
- millisecond()
- min()
- minp()
- minute()
- modify()
- mongo_close ()
- mongo_open()
- mongo_shell()
- month()
- movefile()
- n.f(x)
- name()
- new()
- news()
- next {a}
- nodes()
- not()
- now()
- null
- number()
- olap_close()
- olap_open()
- olap_query()
- or()
- output()
- p()
- pad()
- parse()
- paste ()
- pdate()
- penum()
- periods()
- permut()
- pfind()
- pi()
- pivot()
- pmax()
- pmin()
- pos()
- power()
- prior()
- proc()
- product()
- property()
- pseg()
- pselect()
- psort()
- ptop()
- push()
- query()
- r.(x)
- r.F
- r.F=x
- rand()
- rands()
- range()
- rank()
- ranki()
- ranks()
- read()
- record()
- redis()
- redis_close()
- redis_cluster()
- redis_get()
- redis_getrange ()
- redis_hkeys ()
- redis_hlen ()
- redis_hmget()
- redis_hvals()
- redis_keys()
- redis_lindex()
- redis_llen()
- redis_lrange()
- redis_pool()
- redis_scard()
- redis_sdiff()
- redis_select()
- redis_sentinel()
- redis_shared()
- redis_sharedpool()
- redis_sinter()
- redis_sismember()
- redis_smembers()
- redis_srandmember()
- redis_strlen ()
- redis_sunion()
- redis_type()
- redis_zcard()
- redis_zcount()
- redis_zrange()
- redis_zrangebyscore()
- redis_zrank()
- redis_zscore()
- regex()
- register()
- rename()
- replace()
- report_config()
- report_exportHtml()
- report_exportPdf()
- report_exportXls()
- report_open()
- report_run()
- reset()
- result
- return xi
- rgb()
- right()
- rollback()
- round()
- row()
- run()
- rvs()
- sap_client ()
- sap_close ()
- sap_cursor ()
- sap_excute ()
- sap_getparam ()
- sap_table ()
- savepoint()
- second()
- segp()
- select()
export()
本章介绍export()函数的多种用法。
A.export()
描述:
将序列转成字符串
语法:
A.export(x:F,…;s)
备注:
将序表/排列/序列中的每条记录,选出字段x并用自选分隔符s隔开,结果以字符串形式返回,结果字符串中的字段名为F。
当省略参数x时,输出所有字段,A是序列时生成无名称的单列串。排号按作为整数存。
当省略参数x:F时,若A是包含记录的序列,则记录必须是相同数据结构。
选项:
|
@t |
列名作为第一条记录写在字符串开头 |
|
@c |
无s时用逗号分隔。如果同时有s则用s分隔。 |
|
@j |
导出成json格式串,忽略s |
|
@w |
换行符使用windows风格,即用\r\n,缺省按照操作系统规定。 |
|
@x |
导出成XML格式串,s为起始点,多层用/分隔,s不可省略。 <xml> <table> <row> <F>v</F> … </row> … </table> </xml> |
|
@q |
导出的文本字段值和标题带有引号 |
|
@o |
用引号作为转义符,缺省用java风格的反斜杠\,需要与@q配合使用 |
参数:
|
A |
需要输出的序表/排列/序列 |
|
x |
输出的字段,省略则输出A中所有字段 |
|
F |
字串中的结果字段名,省略则使用原字段名 |
|
s |
字段间自选分隔符,缺省分隔符是tab |
返回值:
字符串
示例:
|
|
A |
|
|
1 |
=demo.query("select EID,NAME from EMPLOYEE") |
|
|
2 |
=A1.export() |
省略x、F和s参数 |
|
3 |
=A1.export(;"|") |
指定分隔符为“|” |
|
4 |
=A1.export@t(EID:id,NAME:name;",") |
指定选出字段和分隔符,并且将列名作为第一条记录写在字符串开头 |
|
5 |
=A1.export@x(NAME;"employee/name") |
将序表转为xml格式的字串返回,分别将employee、name作为第一、第二层节点 |
|
6 |
=A1.export@j() |
将序表转为json格式的字串返回 |
|
7 |
[1,23,34,45] |
序列 |
|
8 |
=A7.export() |
|
|
9 |
=A1.export@c() |
使用@c选项,无s参数时默认用逗号分隔 |
|
10 |
=A1.export@w() |
换行符使用windows风格,即用\r\n |
|
11 |
=["12\r34","aa\nbb"] |
|
|
12 |
=A11.export() |
|
|
13 |
=A11.export@q() |
使用@q选项,导出的内容带有引号 |
|
14 |
=A11.export@qo() |
使用@o选项,使用引号作为转义符 |
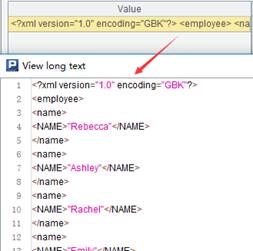
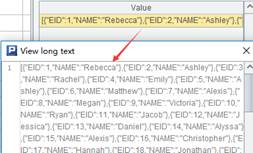
注意:
字符串的格式:记录间用空格隔开,字段间用自选分隔符隔开,缺省为tab键隔开
相关概念:
f.export(A,x:F,…;s)
描述:
将序列/排列/序表写入文件
语法:
f.export(A,x:F,…;s)
备注:
将A以文本形式写入文件f。当文件不存在时,自动创建(但不能自动创建路径目录),创建的文件缺省为文本格式。当A中存在排号类型的字段时,此字段值以整数形式写入。
当A是排列或者序表时,x参数不存在时写入所有字段,A的不可输出字段不能写入文件f,当字段取值为引用记录则写入记录的主键。
当A是序列时,x参数不存在时写入文件f的是无字段名的单列文本。
选项:
|
@t |
将第一条记录作为标题写入文件 |
|
@a |
追加写入,缺省是覆盖原文件中的内容,与@t互斥。追加的内容要与原文件内容。 |
|
@b |
写成二进制文件,速度更快。不支持参数s |
|
@c |
不存在参数s时用逗号分隔;存在参数s时则用s分隔。 |
|
@z |
强制@b,分段写入到二进制文件f中,缺省不分段。强制转化成二进制文件,在@z选项中参数s表示分组表达式,存在参数s时认为A对s有序,仅在s变化时才分段。@z适用于分段导出并行数据量大的二进制文件,导出时同一段的记录不会被拆开。 |
|
@w |
换行符使用windows风格,即用\r\n,缺省操作系统规定 |
|
@q |
导出的文本字段值和标题都带有引号 |
|
@o |
用引号作为转义符,缺省用java风格的\,需要与@q配合使用 |
参数:
|
f |
文件 |
|
A |
需要输出的序表/排列/序列 |
|
x |
需要输出的字段,省略则导出A排列中所有可文本化字段,用#时表示用序号定位 |
|
F |
结果字段名,省略则使用原字段名 |
|
s |
对于文本文件为自选分隔符,缺省默认分隔符是tab |
示例:
– 将排列写入到文本文件中。
|
|
A |
|
||
|
1 |
=demo.query("select * from DEPARTMENT") |
|
||
|
2 |
=file("D:\\Department.txt").export(A1) |
|
||
|
3 |
=file("D:\\Department.txt").export@t(A1) |
@t选项,第一行作为标题写入 |
||
|
4 |
=file("D:\\Department2.txt").export(A1;"|") |
|
||
|
5 |
=file("D:\\Department2.txt").export(A1;) |
|
||
|
6 |
=file("D:\\Department2.txt").export@a(A1) |
接上例,在文件内容的后边追加A1中的内容 |
||
|
7 |
=file("D:\\Department3.txt").export@b(A1) |
写成二进制文件 |
||
|
8 |
=file("D:\\Department4.txt").export@t(A1,DEPT:Dept1;"|") |
x不省略时,只导出指定字段 |
||
|
9 |
[a,s,d,f] |
|
||
|
10 |
=file("D:\\myfile.txt").export(A9) |
myfile.txt为无字段名单列文件 |
||
|
11 |
=file("D:\\Department6.txt").export@c(A1) |
|
||
|
12 |
=demo.query("select * from EMPLOYEE order by GENDER") |
按GENDER排序 |
||
|
13 |
=file("D:\\EMPLOYEE.btx ").export@z(A12,EID,NAME,SURNAME,GENDER,SALARY;GENDER) |
按GENDER分组导入到EMPLOYEE. btx文件中 |
||
|
14 |
=file("D:\\EMPLOYEE.txt").export@w(A1) |
换行符使用windows风格,即用\r\n |
||
|
15 |
=demo.query("select * from DEPARTMENT").keys(MANAGER) |
|
||
|
16 |
=A12.switch(DEPT,A15:DEPT) |
|
||
|
17 |
=file("D:\\EMPLOYEE1.txt").export@t(A16) |
A16中DEPT为引用记录则导出记录的主键 |
||
|
18 |
=demo.query("select * from DEPARTMENT") |
|
||
|
19 |
=file("D:\\Department7.txt").export(A18,#1) |
#1表示第一列,所以只导出了第一列的数据 |
||
|
20 |
=file("D:\\Dep1.txt").export@q(A18,#1) |
|
||
|
21 |
=["12\r34","aa\nbb"] |
|
||
|
22 |
=file("D:\\T1.txt").export@q(A21) |
|
||
|
23 |
=file("D:\\T2.txt").export@qo(A21) |
|
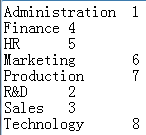


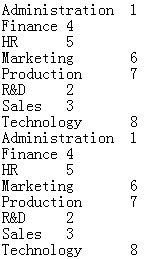


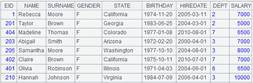
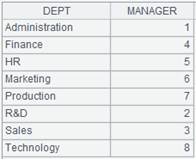


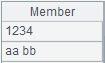
注意:
txt文件的格式:记录间用回车符隔开,字段间用自选分隔符隔开,缺省为tab键隔开
这里A必须是由相同数据结构的记录组成的序列
相关概念:
f.export(cs,x:F,…;s)
描述:
将游标中的数据读出后写入到文本文件中
语法:
f.export(cs,x:F,…;s)
备注:
将游标cs以文本形式写进文件对象f。当文件不存在时,自动创建这个文件(不能自动创建路径目录)。
选项:
|
@t |
以第一条记录作为标题写入文件 |
|
@a |
追加写,如果省略则是覆盖原文件中的内容,与@t互斥。必须保证同构,否则报错。 |
|
@b |
写成二进制文件,速度更快,忽略@t,不支持参数s |
|
@c |
无s时用逗号分隔。如果同时有s则用s分隔。 |
|
@z |
强制@b,分段写入到二进制文件f中,缺省不分段。此选项中s为分组表达式,有s参数时认为cs 对s有序,仅在s变化时才分段。此二进制文件用于并行数据量大时的分段导出,导出时同一段的记录不会被拆开。 |
|
@w |
换行符使用windows风格,即用\r\n,缺省用操作系统规定 |
|
@q |
导出的文本字段值和标题都带有引号 |
|
@o |
用引号作为转义符,缺省用java风格的\,需要与@q配合使用 |
参数:
|
f |
文件对象 |
|
cs |
需要输出的游标数据 |
|
x |
需要输出的字段,省略则导出A排列中所有可文本化字段,用#时表示用序号定位 |
|
F |
结果字段名,省略则使用原字段名 |
|
s |
自选分隔符,缺省默认分隔符是tab |
示例:
– 将游标数据写入到文本文件中。
|
|
A |
|
|
1 |
=demo.cursor("select * from DEPARTMENT") |
|
|
2 |
=file("D:\\Department1.txt").export(A1) |
tab分隔符 |
|
3 |
=demo.cursor("select * from DEPARTMENT") |
|
|
4 |
=file("D:\\Department2.txt").export(A3;"/") |
指定分隔符“/” |
|
5 |
=demo.cursor("select * from DEPARTMENT") |
|
|
6 |
=file("D:\\Department3.txt").export@t(A5) |
以第一条记录作为标题写入文件 |
|
7 |
=demo.cursor("select * from DEPARTMENT") |
|
|
8 |
=file("D:\\Department4.txt").export@t(A7,DEPT:Dept1,DEPT:Dept2;"|") |
x不省略时,导出指定字段 |
|
9 |
=demo.cursor("select * from DEPARTMENT") |
|
|
10 |
=file("D:\\Department5.txt").export@t(A9,DEPT,MANAGER;"/") |
省略F则使用原字段名。 |
|
11 |
=demo.cursor("select * from DEPARTMENT") |
|
|
12 |
=file("D:\\Department5.txt").export@a(A11,DEPT,MANAGER;"/") |
接上例,在Department5.txt内容的后边追加A12中的内容 |
|
13 |
=demo.cursor("select * from DEPARTMENT") |
|
|
14 |
=file("D:\\Department6.txt").export@b(A13) |
写成二进制文件,速度更快 |
|
15 |
=demo.cursor("select * from DEPARTMENT") |
|
|
16 |
=file("D:\\Departmen7.txt").export@c(A15) |
使用逗号作为分隔符 |
|
17 |
=demo.cursor("select * from EMPLOYEE order by GENDER") |
按GENDER排序 |
|
18 |
=file("D:\\EMPLOYEE1.btx ").export@z(A17,EID,NAME,SURNAME,GENDER,SALARY;GENDER) |
导出分段二进制文件,按GENDER分组导出到EMPLOYEE. btx文件中 |
|
19 |
=demo.cursor("select * from EMPLOYEE order by GENDER") |
|
|
20 |
=file("D:\\EMPLOYEE2.txt").export@w(A19) |
换行符使用windows风格,即用\r\n |
|
21 |
=demo.cursor("select * from DEPARTMENT") |
|
|
22 |
=file("D:\\Department8.txt").export(A21,#1) |
#1表示第一列,所以结果导出游标中的第一列的数据 |
|
23 |
=file("D:\\Dep1.txt").export@q(A21) |
导出的文本字段值和标题都带有引号 |
|
24 |
=["12\r34","aa\nbb"].cursor() |
游标中的数据内容:
|
|
25 |
=file("D:\\Dep2.txt").export@q(A24) |
|
|
26 |
=file("D:\\Dep3.txt").export@qo(A24) |
用引号作为转义符
|









相关概念: