长语句
在集算器中,有一些特殊的代码书写方式,可以使代码更为整齐,提高可读性。在这里我们来了解一下长语句和子计算语句的使用。
长语句
对于某些较长的表达式写在一个格内看不全,可以用续格规则写在多个单元格中。续格规则就是指在计算格或执行格以字符,(逗号)或 ;(分号)结尾时,将自动拼接下一格内容,直到不是这些字符结尾或本行(代码块)结束。如:
|
|
A |
B |
C |
|
1 |
==["one","two", |
"three","four", |
"five"] |
|
2 |
==create(Field1, |
Field2, |
Field3) |
|
3 |
==demo.query( |
"select NAME, |
STATEID from CITIES") |
|
4 |
==A3.groups( |
STATEID; |
count(~):Count) |
|
5 |
>>C5=A4.( |
Count) |
|
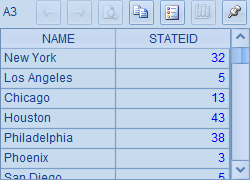
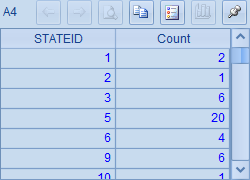
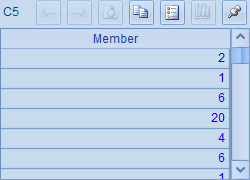
例子中,每一行都是一个长语句。长语句需要用双等号"=="或者双大于号">>"开头,对于这样的写法集算器将用续格规则拼接表达式。对于==开端的表达式,计算结果将存储在首格中。A1,A2,A3和A4中计算后的结果分别如下:

A5中的长语句用来为C5赋值,C5中的值如下:
从例子中可以看到,在长语句中,可以使用各种函数,只需保证前方的单元格均以 ,;( 等字符结尾。
长语句在用于if,case等函数时,可以使表达式的结构显得更为清晰,如:
|
|
A |
B |
C |
D |
|
1 |
Position |
F |
|
|
|
2 |
==case(B1, |
"C":"Center", |
"F":"Forward", |
"G":"Guard") |
|
3 |
Month |
7 |
|
|
|
4 |
==if(B3<=3:"Q1", |
B3<=6:"Q2", |
B3<=9:"Q3", |
"Q4") |
A2中将比赛中场上位置的缩写转为对应的单词。A4中计算B3中的月份属于第几季度。A2和A4中的计算结果分别如下:
![]()
![]()
长语句除了可以用在同一行中,还可以使用在代码块里。此时,以长语句的首格为主格,代码块中的单元格均作为续格。如:
|
|
A |
B |
C |
|
1 |
Air Quality Index |
[59,164,50,104,93] |
|
|
2 |
=B1.(func(A3,~)) |
|
|
|
3 |
func |
==if( |
A3>300:"Hazardous", |
|
4 |
|
|
A3>200:"Very Unhealthy", |
|
5 |
|
|
A3>150:"Unhealthy", |
|
6 |
|
|
A3>100:"Unhealthy for Sensitive Groups", |
|
7 |
|
|
A3>50:"Moderate", |
|
8 |
|
|
"Good") |
|
9 |
|
return B3 |
|
在这个例子中,长语句用在A3的子程序中,根据空气质量指数返回对应的等级。长语句所在区块的主格是B3,续格是C3~C8。A2调用子程序计算一批AQI数据对应的质量等级,A2中结果如下:

集算器处理长语句时,会将长语句首格为主格的代码块,整个作为一条语句处理。否则会依次执行该代码块中的单元格,可能会导致错误。
子计算语句
上面的例子中,在计算一批AQI数据对应的空气质量等级时,使用了子程序。子程序的功能是计算每一个AQI数据对应的空气质量等级。A2中的表达式也可以不用子程序,直接写在一个表达式中:=B1.(if(~>300:"Hazardous",~>200:"Very Unhealthy",~>150:"Unhealthy",~>100:"Unhealthy for Sensitive Groups",~>50:"Moderate","Good")),这样的表达式显得繁冗而不易理解。除了使用子程序,在集算器中还可以使用子计算语句来处理这样的计算:
|
|
A |
B |
C |
|
1 |
Air Quality Index |
[59,164,50,104,93] |
|
|
2 |
==B1.(??) |
=if( |
~>300:"Hazardous", |
|
3 |
|
|
~>200:"Very Unhealthy", |
|
4 |
|
|
~>150:"Unhealthy", |
|
5 |
|
|
~>100:"Unhealthy for Sensitive Groups", |
|
6 |
|
|
~>50:"Moderate", |
|
7 |
|
|
"Good") |
A2中的计算结果和前一个例子是相同的。我们可以发现,子计算语句与子程序的写法有些类似。子计算语句的主格需要用双等号"=="开头,在以它为主格的代码块中,可以使用长语句,而不必再加双等号或双大于号。子计算语句主格中使用双问号"??"运算符,代码块中,最后执行的一个计算格的值将自动返回,而不需使用return语句。另外需要注意的是,子程序可以在网格中的任何地方调用,而子计算语句只在主格中调用。
上面的子计算语句中只有一个使用if()函数的长语句,在子计算语句的代码块中,也可以使用多条语句,如:
|
|
A |
B |
C |
|
1 |
Air Quality Index |
[59,164,50,104,93] |
|
|
2 |
==B1.(??) |
if ~>300 |
="Hazardous" |
|
3 |
|
else if ~>200 |
="Very Unhealthy" |
|
4 |
|
else if ~>150 |
="Unhealthy" |
|
5 |
|
else if ~>100 |
="Unhealthy for Sensitive Groups" |
|
6 |
|
else if ~>50 |
="Moderate" |
|
7 |
|
else |
="Good" |
此时,子计算语句的代码块中不再只有1个计算格,在每次计算时,将返回最后执行的计算格的值。如对于93,在代码块中最后执行的计算格是C6中的="Moderate",将返回结果Moderate。注意C列中需要写表达式而不能用常数单元格。A2中的结果与前面是相同的:
子计算语句可以看为一种特殊的长语句,整个子计算语句的目的就是完成主格中表达式的计算。
使用子计算语句,可以完成一些比较复杂的计算。如,根据州数据表STATES和大城市数据表CITIES,找出哪些州中人口最多的2个城市的人口总数超过2,000,000。解答如下:
|
|
A |
B |
C |
|
1 |
=demo.query("select STATEID,ABBR, NAME from STATES order by STATEID") |
|
|
|
2 |
==A1.select(??) |
=demo.query("select * from CITIES where STATEID=?",STATEID) |
|
|
3 |
|
if B2.len()<1 |
=false |
|
4 |
|
else if B2.len()==1 |
=B2(1).POPULATION>2000000 |
|
5 |
|
else |
=B2.sort(-POPULATION) |
|
6 |
|
|
=C5(1).POPULATION+ C5(2).POPULATION>2000000 |
先在A1中选出所有州数据。接下来,在A2中使用子计算语句,根据代码块中的结果来判断每个州是否满足条件。其中,B2中查询出这个州的大城市,并根据结果进一步判断。如果未找到大城市数据,则在C3中用=false返回,说明不满足要求。如果仅有1个大城市的数据,那么在C4中检查这个城市是否已经满足人口超过2,000,000。如果查询到2个或更多城市的数据,则在C5中根据人口降序排序,并在C6中判断是否满足要求。通过使用子计算语句,复杂查询的结构更为清晰。计算后,A2中的结果如下: