代码块
在集算器入门之单元格类型中,我们了解到了在集算器中,单元格可以分为常数格、计算格、执行格、注释格等多种类型。与此类似,集算器中用代码块书写的一些代码,也可以分为计算块、赋值块、执行块和注释块类型。
计算块
在5.2长语句中,我们将了解长语句和子计算语句。它们主格的格串均以==开头而非=,集算器在计算时,会将以该格为主格的整个代码块视为一个语句,要整体计算,而不可拆开。集算器在按规则执行完本条语句后将忽略本代码块中的其它单元格。如:
|
|
A |
B |
C |
|
1 |
==demo.query( |
"select NAME as CITY, |
|
|
2 |
|
STATEID as STATE from CITIES") |
|
|
3 |
==A1.select(??) |
=demo.query( |
"select * from STATES where STATEID=?", |
|
4 |
|
|
STATE) |
|
5 |
|
if left(B3.ABBR,1)=="N" |
>STATE=B3.NAME |
|
6 |
|
|
=true |
|
7 |
|
else |
=false |
在上面的代码中,前2行是A1为主格的长语句,查询出城市信息如下:
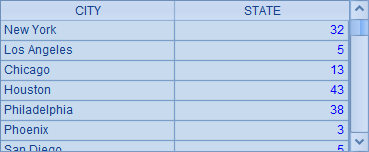
代码中的3~7行,是以A3为主格的子计算语句,从城市信息中,查询出所在州的简称以"N"开头的城市,并将它们的STATE字段赋值为州的名称。A3的计算结果如下:
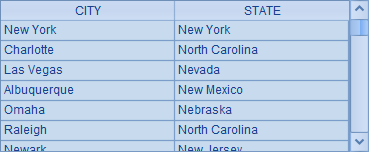
这种以"=="开头的语句块又称为计算块,计算块其实就是一个计算语句。写在单行中的长语句或者子计算语句,其实也同样可以视为计算块。
一个代码块,它的主格就是起始格,我们再来了解一下什么是代码块格。
如果满足:主格所在行下面的各行中,主格所在列及该列左侧的所有单元格均为空格,则这些行及主格所在行一起构成主格的代码块;直到在某一行中,主格所在列或其左侧的任一个单元格非空,则自该行起的各行均不再属于代码块。
|
|
A |
B |
C |
D |
|
1 |
|
|
|
|
|
2 |
|
>Code begin |
|
|
|
3 |
|
|
|
|
|
4 |
|
|
|
|
|
5 |
|
|
|
|
|
6 |
Not null |
Not null |
|
|
在上面的网格中,如果B2是代码块的主格,如果满足绿色区域为空格,则第2~5行构成了主格B2的代码块。红色区域中的A6或B6中任一个格子不是空格,无论是代码格、计算格、执行格、常数格甚至是注释格,都意味着从第6行起不再是B2的代码块。
代码块并非仅用于一条语句,也经常用来在主格中放置语句,实现循环流程或分支流程等,如:
|
|
A |
B |
C |
|
1 |
=demo.query("select NAME as CITY, STATEID as STATE from CITIES") |
[] |
|
|
2 |
for A1 |
=demo.query("select * from STATES where STATEID=?",A2.STATE) |
|
|
3 |
|
if left(B2.ABBR,1)=="N" |
>A2.STATE=B2.NAME |
|
4 |
|
|
>B1=B1|A2 |
上面的代码中,使用了代码块,但是没有使用长语句或者子计算语句。其中A2为主格的代码块实现循环计算,B3为主格的代码块执行判断流程。B1中获得的结果同样是所在州的简称以"N"开头的城市。
我们在这里研究的代码块类型,并不包括这种用语句实现各种流程的情况,而是指用续格规则写在多个单元格中,执行时视为一个语句的代码块。续格规则就是指在计算格或执行格以字符 ,;( 结尾时,将自动拼接下一格内容,直到不是这些字符结尾或本代码块结束。
赋值块与执行块
计算块以==开头,效果类似于计算格。当代码块中的表达式并不返回结果时,可以用>>开头,同样使用续格规则,表示以该格为主格的整个代码块是一个语句。如:
|
|
A |
B |
C |
|
1 |
==demo.query("select NAME as CITY, |
POPULATION from CITIES") |
|
|
2 |
>>C1=A1.select( |
left(CITY,1):"C", |
|
|
3 |
|
POPULATION>500000:true) |
|
A2中的长语句并不返回结果,而是用来找出名称以"C"开头,且人口大于500,000的城市数据,把结果赋值给C1。计算后,C1中结果如下:

这种用来赋值的代码块,称为赋值块。
有的长语句也不是用来赋值的,而是用来执行某种操作,如:
|
|
A |
B |
|
1 |
=connect@e("demo") |
=A1.query("select * from EMPLOYEE") |
|
2 |
>A1.execute("drop table EMPLOYEE1") |
|
|
3 |
>>A1.execute("create table EMPLOYEE1( |
EID int,FULLNAME varchar(30), |
|
4 |
|
GENDER varchar(10))") |
|
5 |
>>A1.execute(B1, |
"insert into EMPLOYEE1(EID, |
|
6 |
|
FULLNAME,GENDER) values(?,?,?)", |
|
7 |
|
EID,NAME+" "+SURNAME, GENDER) |
|
8 |
=A1.query("select * from EMPLOYEE1") |
>A1.close() |
其中,A3中的代码块用来在数据库中创建EMPLOYEE1表,A5中的代码块用来根据B1中的数据向EMPLOYEE1中插入记录。插入记录完成后,在A8中查询到的结果如下:

A3和A5中的这种代码块,称为执行块。执行后与赋值块,只是根据代码块的作用来划分的。
注释块
类似地,当单元格的格串以//开头时,表示以该格为主格的整个代码块都是注释。这个代码块称为注释块。集算器碰到这种格串时会直接跳过整个注释块。如:
|
|
A |
B |
|
1 |
//comment |
1.note... |
|
2 |
|
2.note... |
|
3 |
|
3.note... |
|
4 |
|
=1+1 |
|
5 |
=1+1 |
|
在以A1为首格的代码块中,所有单元格均被视为注释,而不需像注释格一样以/字符开头,即使B4单元格也同样被作为注释处理。A5单元格非空,标志着代码块结束,A5格中的表达式被正常解析计算。
与计算块,赋值块与执行块不同,注释块中并非需要执行的表达式,因此也不要求续行规则。