Excel
集算器可以将Excel作为数据源,实现excel文件的读取和写入。这里通过几个简单的例子来看一下具体的做法。
首先,看一下文件读取。读取的目标是data.xlsx和data.xls(excel97-2000格式)。两个文件的内容一样,sheet0的名称是employee,sheet1的名称是orders。
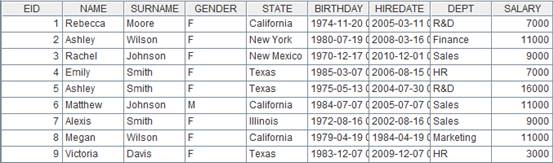
Employee的内容是:

Orders内容是:
读取excel的集算器脚本如下:
|
|
A |
|
1 |
=file("D:/files/work/excel/data.xlsx") |
|
2 |
=file("D:/files/work/excel/data.xls") |
|
3 |
=A1.xlsimport@tx() |
|
4 |
=A2.xlsimport@t(ORDERID,SELLERID,AMOUNT,ORDERDATE;"orders",3:-3) |
A1:定义一个文件对象,路径和文件名是:D:/files/work/excel/data.xlsx。
A2:定义一个文件对象,路径和文件名是:D:/files/work/excel/data.xls。
A3:用xlsimport函数读取A1的文件对象内容。@tx是函数选项,t是指第一行是标题,如果不带t选项的话,集算器会用“_1,_2…”来命名各列。x是指文件时xlsx格式,如果不带x选项的话,集算器会根据文件后缀来判断,判断不出的话,就按照xls读取。因为xlsimport函数没有其他输入参数,所以读取的结果是第一个sheet页的全部数据,如下:
A4:用xlsimport函数读取A2的文件内容。@t选项是指第一行是标题。输入参数ORDERID,SELLERID,AMOUNT,ORDERDATE是指仅仅导入指定的这些列,未指定的不导入。"orders"参数是指导入名称为orders的sheet页。3:-3参数是指从第3行开始,导入到倒数第3行。也可以导入第3行到第100行的数据,写为:3:100。需要注意的是,当设定了导入的起始行时,使用了@t选项,要求标题行在指定的起始行。如例子中需要标题行在第3行,否则无法获得正确的表结构。
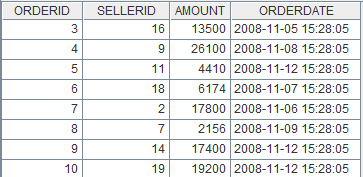
导入的结果是:
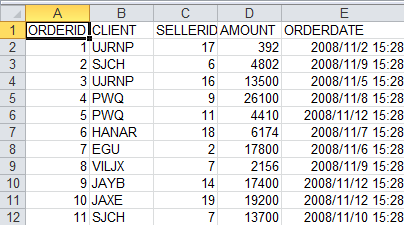
再来看一下写入excel文件。假设我们要把上述A3、A4的结果导入到result1.xlsx、result2.xls文件中。A3的结果导入到名字叫r-emp的sheet;A4的结果导入到名字叫r-orders的sheet。
写入excel的集算器脚本如下:
读取excel的集算器脚本如下:
|
|
A |
|
1 |
=file("D:/files/work/excel/data.xlsx") |
|
2 |
=file("D:/files/work/excel/data.xls") |
|
3 |
=A1.xlsimport@tx() |
|
4 |
=A2.xlsimport@t(ORDERID,SELLERID,AMOUNT,ORDERDATE;"orders",3:-3) |
|
5 |
=file("D:/files/work/excel/result1.xlsx") |
|
6 |
=file("D:/files/work/excel/result2.xls") |
|
7 |
>A5.xlsexport@tx(A3,EID:EMPLOYEEID,NAME;"r-emp") |
|
8 |
>A6.xlsexport(A4;"r-orders") |
A5、A6:按照要求定义两个文件对象。
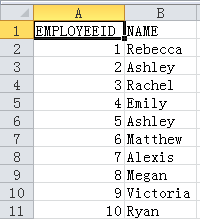
A7:使用xlsexport函数,将A3的内容导入到文件A5中。xlsexport的@tx选项是指导出的格式是xlsx格式,并且第一行导出的是字段标题。xlsexport函数的输入参数A3,是要导出的序表。参数EID:EMPLOYEEID,NAME是指定要导出的字段,其中EID:EMPLOYEEID是指EID字段导出的时候重命名为EMPLOYEEID。参数"r-emp"指定导出的sheet名称。最终导出的excel文件内容如下:
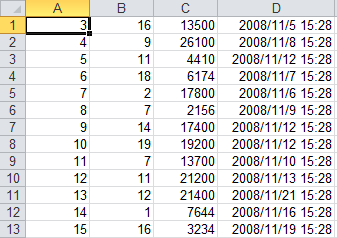
A8:使用xlsexport函数,将A4的内容导入到文件A6中。xlsexport的没有使用@tx选项,因此导出的格式是根据文件后缀判断出的xls格式,并且第一行不导出字段标题。xlsexport函数的输入参数A4,是要导出的序表。因为输入参数没有指定要导出的字段,所以导出全部字段。参数"r-orders"指定导出的sheet名称。最终导出的excel文件内容如下:
除了使用序表以外,集算器中还可以将游标中的数据导出到excel文件中,如:
|
|
A |
|
1 |
=file("D:/files/work/excel/data.xlsx") |
|
2 |
=demo.cursor("select * from EMPLOYEE") |
|
3 |
=A5.xlsexport@txs(A2;"employee2") |
由于使用游标数据时,需要处理的数据量经常会很大,因此在xlsexport函数中添加了@s选项,采用流式处理。由于导出excel文件之前会读入文件,因此导出大数据时,需要注意原始的xlsx文件不能太大。由于excel本身的限制,导出xlsx文件时,当导出一个sheet的数据已满1000,000条时,会自动停止。
除了导入与导出外,集算器中也可以使用xo.xlscell(a:b,s,t)函数修改名为s的sheet中,单元格c的值为t,t中的文本可以用制表符Tab隔开表示多列,或者用回车符隔开表示多行。如:
|
|
A |
|
1 |
=file("D:/files/work/excel/data.xls") |
|
2 |
=A1.xlsopen() |
|
3 |
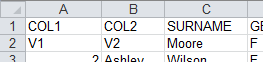
=A2 .xlscell("A1","employee";"COL1\tCOL2\nV1\tV2") |
A3中,修改data.xls文件,在employee页中,从A1格开始修改数据,字串t包含了制表符和回车符,修改后,A1,B1,A2,B2中的数据都被修改,结果如下: