服务器
并行计算(Parallel Computing),是指在解决计算问题时,将一个复杂任务拆分为多个子任务,这些子任务分配给多个服务器计算,每个子任务计算完成后,计算结果各自返回,在主任务中再将所有结果汇总。使用并行计算,可以同时使用更多的计算资源解决问题,可以有效地提升计算速度和数据处理能力。
并行计算可以分为单机使用的多线程计算,以及在多台计算机构成的集群系统中使用的并行计算,我们通常提到的并行计算主要指后面的一种。
我们在这里将了解如何在集算器中并行服务器的使用及配置,并在此基础上初步认识并行计算。
集算器中的并行服务器
集群计算时,集群体系由多个分机(sub node)构成,指挥分机工作的进程称为主机(main node),分机运行时,可以接收计算请求,并计算本地的网格文件,将计算结果返回到主机。在集群网络中,分机可以在多台不同的计算机中运行;每个分机上可运行一个或者多个进程(process),进程以分机IP地址和端口号标识。所有运行中的服务器,共同构成并行计算的分机系统。一个分机上运行的多个进程被称为分进程,其中存在一个主进程,用来管理分机上所有的分进程。
集算器提供了服务器类com.raqsoft.ide.dfx.UnitServerConsole,可以根据配置文件获取地址和端口,启动并行服务器。
在集算器并行体系下没有中心并行管理器,每次执行时临时指定可使用的机器。
在每个并行计算任务中都有逻辑中心,主机向分机发出任务,并回收结果以归并。在执行过程中,如果主机发生错误则任务将会失败;如果分机发生错误,主机会重新分配这个子任务,寻找另一个可以的分机来执行。如果想详细了解集算器中并行任务的执行情况,请阅读10.2集群计算。
数据也可以存放在可被节点机访问到的网络文件系统中(Network File System),比如HDFS。由NFS管理冗余数据以确保容错能力比使用节点机更简单些,但与节点机本地文件读取的机制相比,采用NFS存储数据时会由于网络传输造成性能损失。
并行服务器配置
在集算器安装目录的esProc\bin路径下,可以找到esprocs.exe文件,可以直接运行它来启动或配置服务器。使用esprocs时,会自动在安装路径下加载所需的jar包,但是需要注意此时使用的配置文件raqsoftConfig.xml和unitServer.xml必须放置在集算器安装目录的esProc\config路径下。运行后,打开窗口如下:
在esprocs.exe执行时,窗口中会显示加载初始设定的信息,这些设定实际上是由配置文件raqsoftConfig.xml决定的。在右侧的菜单栏中点击Config,可以配置并行服务器的相关信息,点击后弹出服务器配置窗口如下:
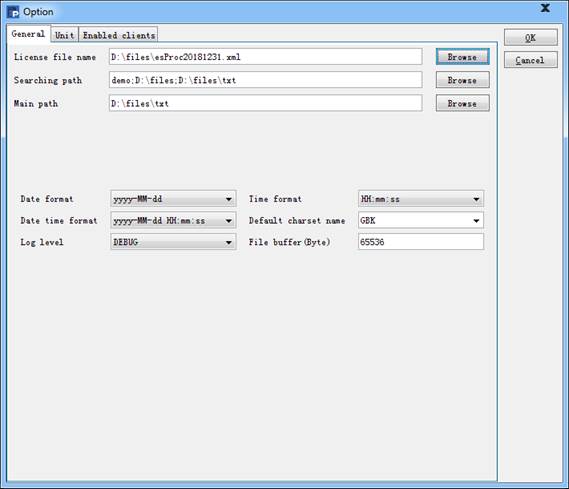
在General页面中,可以配置授权文件、主路径、寻址路径、日期时间格式、默认字符编码、日志等级、文件缓存区字节数等信息。其中,日志级别Log level可为OFF, SEVERE, WARNING, INFO, DEBUG等,优先级依次降低,若为OFF则不输出任何日志信息;若为INFO,则只输出SEVERE,WARNING,INFO等各级别的信息,依次类推。
这里的配置信息,实际上和集算器IDE中的对应配置是同步的,这些信息,也可以在菜单栏中点击Tool>Options,在选项设定的Environment页面中查看或修改:
下面我们继续来了解并行服务器的配置,在Unit页面中可以配置分机信息,如下:
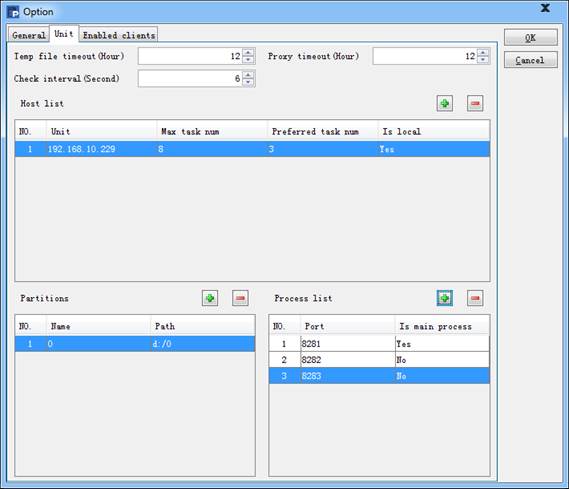
Temp file timeout设定临时文件的生命周期小时数;Check interval必须设定为正值或0,为检查过期的间隔秒数;Proxy timeout为代理生命周期,即远程游标、任务空间的生命小时数。如果Temp file timeout或者Proxy timeout设定为0,则不检查过期。
分机列表Host list中,可以配置本机上所有可能用来运行服务器的分机,配置它们的IP地址,在进程列表Process list中,可以为一个IP地址配置多个进程的端口Port,其中第一个为主进程。服务器启动时,会自动在分机列表中,寻找未被占用的IP和端口。需要注意的是,IP地址需要是本机的真实IP,在使用多网卡的情况下可以设定多个IP。
分机配置中,Max task number是该分机允许执行的最大作业数,而Preferred task number是该分机的适合作业数,当分机中使用了多个进程时,适合作业数就是分进程的总数。在Partitions一栏中,可以选择每个分机上所使用的分区。
并行服务器的Enable clients页面中可以设定客户端白名单,如下:
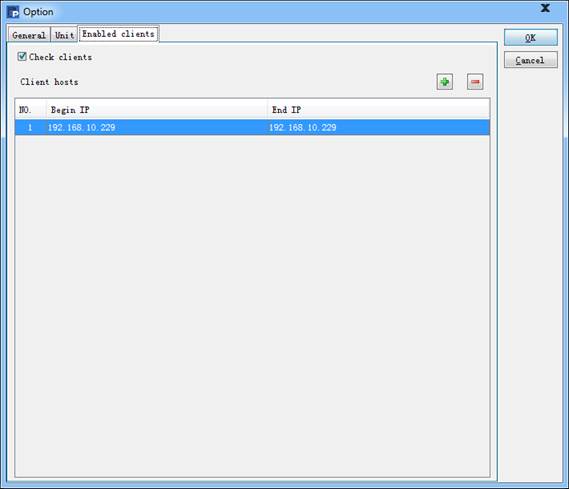
选定Check clients后,可以在Clients hosts列表中,设定允许调用并行服务器的IP地址白名单,不在设定范围中的IP地址将无法调用并行服务器执行计算。
并行服务器设定完成后,点击OK,此时可以自动设定对应的配置文件unitServer.xml如下:
<?xml version="1.0" encoding="UTF-8"?>
<SERVER Version="3">
<TempTimeOut>12</TempTimeOut>
<Interval>1800</Interval>
<ProxyTimeOut>12</ProxyTimeOut>
<Hosts>
<Host ip="192.168.10.229" maxTaskNum="8" preferredTaskNum="3">
<Partitions>
<Partition name="0" path="d:/0">
</Partition>
</Partitions>
<Units>
<Unit port="8281">
</Unit>
<Unit port="8282">
</Unit>
<Unit port="8283">
</Unit>
</Units>
</Host>
</Hosts>
<EnabledClients check="true">
<Host start="192.168.10.229" end="192.168.10.229">
</Host>
</EnabledClients>
</SERVER>
运行并行服务器
并行服务器配置完成后,在分机运行窗口中,点击Start即可开始运行并行服务器,需要停止服务可以点击Stop,服务器停止后可以点击Quit退出。如果点击Reset,服务将初始化重新启动,清除所有的全局变量以及内存区。
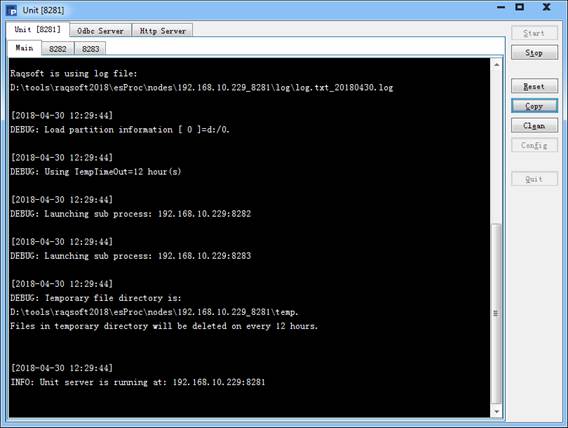
可以发现,在分机启动时,设置的各个进程会同时启动,可以点击Main查看分机主进程的执行情况,或者点击对应的端口号查看分机的其它分进程执行页面。
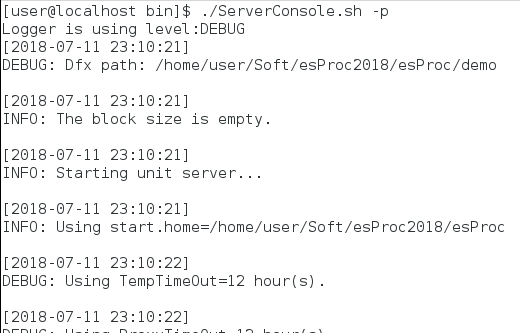
在Linux系统中,可以运行ServerConsole.sh来启动并行服务器类:
![]()
打开的分机运行窗口和在Windows下是相同的:
此外,还可以在执行命令时添加-p参数,非图形启动并行服务器,此时并行服务器将直接执行:
数据存储
为了管理并行网络中并行服务器及各个服务器中正在执行的任务,集算器中提供了数据存储服务。
在集算器安装目录的esProc\bin路径下,可以找到datastore.exe文件(Linux下用datastore.sh),点击即可弹出下示窗口:
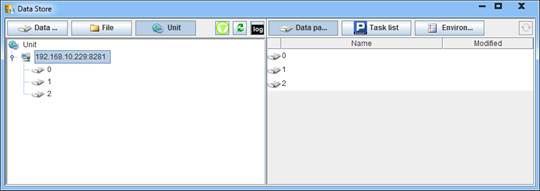
在数据存储界面中,点击搜索节点机按钮![]() 可以搜索当前网络中的分机,并在列表中展示。选择运行中的服务器,还可以在右侧查看该服务器信息,如查看分区情况,或者查看服务器中正在执行的任务列表,并允许强制终止某个任务。当子程序的任务被终止时,主程序也会中断计算。
可以搜索当前网络中的分机,并在列表中展示。选择运行中的服务器,还可以在右侧查看该服务器信息,如查看分区情况,或者查看服务器中正在执行的任务列表,并允许强制终止某个任务。当子程序的任务被终止时,主程序也会中断计算。
并行服务器的使用
当并行服务器已经开始工作后,就可以在网格中通过callx命令分配计算任务到各个服务器了。如下面的网格parallel01.dfx:
|
|
A |
|
1 |
=file("D:/files/txt/PersonnelInfo.txt") |
|
2 |
=A1.import@t(;pPart:pAll) |
|
3 |
=A2.select(State==pState) |
|
4 |
return A3 |
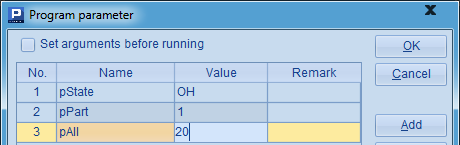
这个网格中的代码,从人员信息文件PersonnelInfo.txt中,读取一部分数据,并从中选出指定州的员工数据。其中用到的网格参数如下:
在主程序中,使用集群并发计算调用parallel.dfx,来计算全部Ohio州的员工:
|
|
A |
|
1 |
[192.168.10.229:8281] |
|
2 |
=callx("D:/files/dfx/parallel01.dfx","OH",to(20),20;A1) |
|
3 |
=A2.conj() |
其中,A1指定计算时调用的并发服务器列表,A2中用callx调用这些服务器来执行并发计算。计算后,A2中的结果如下:
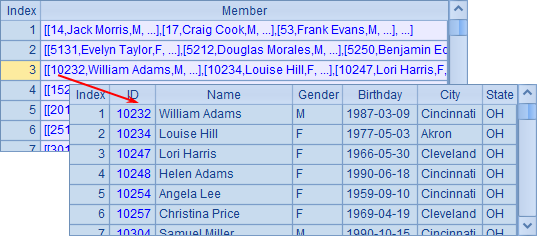
可见,在使用集群服务器时,一个任务会根据参数的数量拆分为多个工作,交由集群服务器去执行。而每个分机又会将工作分配给各个进程去处理,每个进程都会返回一个结果,A2中的数据是就是每个结果排列构成的序列。在A3中将结果合并后,如下:
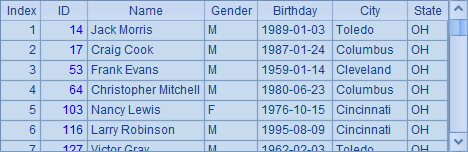
通过这种方法,主程序可以把复杂运算或者大数据量的运算,拆分成多个小任务,交由多个并行服务器分别计算,并在主程序中整合结果。关于并行计算的详细讲解,将在10.2集群计算 中继续。