集群计算
在集算器中,可以使用集群计算来完成复杂的分析处理工作。在网络中独立的多台计算机上的多个并行服务器,共同组成了集群系统。在网络中的任何一台计算机,均可向集群网络发送并行计算请求。
集群系统聚集了多个服务器的计算能力,能够大幅提高性能,又可以随时根据需要扩充规模,同时又不必付出大型计算机的高额成本。
集群计算与 callx 函数
在 10.1服务器 中,我们了解了在集算器中如何启动并行服务器。当多台并行服务器已经启动,构成了集群系统之后,就可以通过callx函数来执行集群计算了。集算器中的并行计算,将由各台服务器来执行任务,计算指定的dfx文件,并返回结果。
使用集群计算时,先需要准备在子任务计算时使用的网格文件,如下面的CalcStock.dfx:
|
|
A |
B |
|
1 |
>output@t("calc begin, SID="+string(arg1) +". ") |
=file("StockRecord.txt").cursor@t() |
|
2 |
=B1.select(SID==arg1) |
=A2.fetch() |
|
3 |
=B2.count() |
=B2.max(Closing) |
|
4 |
=B2.min(Closing) |
=round(B2.avg(Closing),2) |
|
5 |
>output@t("calc finish, SID="+string(arg1) +". ") |
return A3,B3,A4,B4 |
StockRecord.txt文件中存储了一些股票在一段时间内的收盘价格。在每个子任务中,统计指定股票代码的交易信息,包括总交易天数,最高收盘价,最低收盘价,平均收盘价。其中平均收盘价只是简单按日计算均值,不考虑交易笔数。为了了解子程序的执行情况,在开始计算及返回结果前,用output@t函数输出了时间及提示文字。其中,arg1为参数传入股票代码,因为需要在并行计算时设定,所以必须选中Set arguments before run:
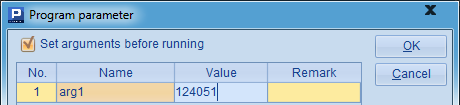
在并行计算时,所有运行并行服务器的计算机中,均需要存在子任务使用的网格文件CalcStock.dfx,这个文件需要存储在各个服务器配置的mainPath中。
在本例中,运行1个分机A,IP地址是192.168.10.229:8281,分机上共运行3个进程,端口分别为8281,8282和8283,将这三个进程依次命名为Ⅰ、Ⅱ和Ⅲ。
此时,即可在网络中任何一台计算机上,在主程序中使用callx函数执行并行计算:
|
|
A |
|
1 |
[192.168.10.229:8281] |
|
2 |
[124051,128857,131893,136760,139951,145380] |
|
3 |
=callx("CalcStock.dfx",A2;A1) |
|
4 |
=A3.new(A2(#):SID,~(1):Count,~(2):Maximum,~(3):Minimum,~(4):Average) |
A3的表达式,callx的参数中,分号前为计算网格文件时使用的参数,在并行计算时,将按照参数中的序列类型参数将计算任务拆分为多个子任务,参数序列的长度就是子任务的个数;如果需要使用多个参数,用逗号分隔;其中的单值参数将复制到各个子任务中。callx的参数中,分号后为分机序列,其中每个分机的描述均为一个字符串,格式为分机主进程的"地址:端口号",如"192.168.10.229:8281"。调用并行服务器完成计算后,需用return返回结果;如果返回多个数据,将会构成序列返回。
例子中共需计算6支股票的数据,代码分别为:124051,128857,131893,136760,139951,145380,将其对应的工作分别设为a,b,c,d,e,f,在并行计算时6个工作交由分机分配计算。当任务总数恰好与分机列表长度相同时,任务会一一对应分配给各个分机,否则将会考察分机计算力来分配,分机计算力较高的分机会被首先分配工作,每次被分配的工作数即为分机的适合作业数。如果分机未启动或者没有空闲进程,则继续查看列表中的下一个分机。分机接受任务后,会将工作分配给各个进程来执行,进程完成计算后会被分配新的任务。可以从各个进程的系统信息输出窗口中,看到任务的分配和执行情况:
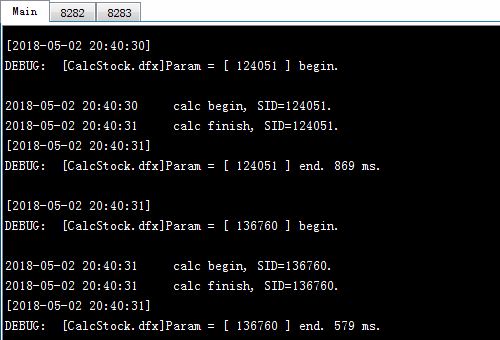

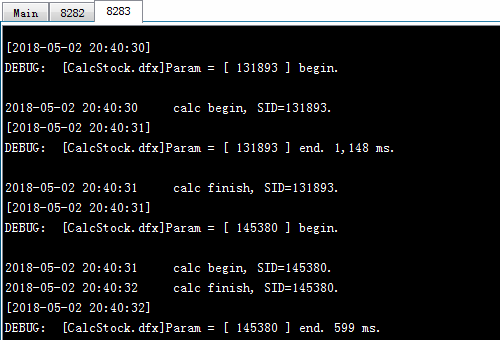
根据系统输出信息可以看到,进程Ⅰ上执行了工作a和d;进程Ⅱ上执行了工作b和e;分机Ⅲ上执行了工作c和f。从任务执行时间可以进一步分析:由于分机使用了3个分进程,因此适合作业数是3,第一次将被分配3个工作,工作a, b和c分别交由3个进程执行,剩余的工作d, e和f将处于等待状态,等进程空闲后再执行分配。
计算后,可以在A4中查看结果:
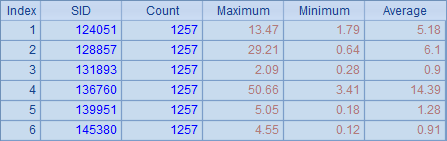
这个例子通过集群运算,将主任务需要处理的大量数据拆分,使得每个进程只处理部分数据,能够充分利用计算机的计算能力以提高计算效率,也可以使用多台分机来有效地避免大数据量造成的内存溢出。
需要注意的是,工作是由每个线程各自执行的,因此各个工作之间要各不相关。在每个分机上,都必须存储着使用的dfx文件,如果在运算时需要使用数据源或者数据文件,则使用的分机需要有相应的数据源配置,或者存储着相应的数据文件。
再来看下面的例子,仍然是计算6支股票的统计数据,与前面不同的是每个子任务只统计某1年的数据,使用的网格文件CalcStock2.dfx如下:
|
|
A |
B |
|
1 |
>output@t("calc begin, year: "+string(arg1)+". ") |
=file("StockRecord"+string(arg1)+".txt") |
|
2 |
=B1.cursor@t() |
[124051,128857,131893,136760,139951,145380] |
|
3 |
=A2.select(B3.pos(SID)>0).fetch() |
=A3.groups(SID;count(~):Count,max(Closing):Maximum,min(Closing):Minimum,sum(Closing):Sum) |
|
4 |
>output@t("calc finish, year: "+string(arg1)+". ") |
return B3.derive(arg1:Year) |
每年的股票数据存储在不同数据文件中,如2010年的数据存储在StockRecord2010.txt中。计算时会用到2010年至2014年共5个数据文件。在每个工作中,统计各股票在指定年份的交易信息。同样,在开始计算及返回结果前,用output@t函数输出了时间及提示文字。
其中,arg1为参数,传入统计年份,并在B4返回的结果中添加,以备查看任务的计算情况:
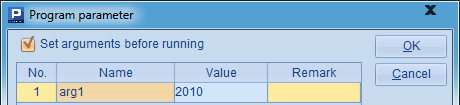
此时,在主程序中执行集群计算如下:
|
|
A |
|
1 |
[192.168.10.229:8281] |
|
2 |
[2010,2011,2012,2013,2014] |
|
3 |
=callx("CalcStock2.dfx":~~|~,A2;A1) |
|
4 |
=A3(1).group(SID;~.max(Maximum):Maximum,~.min(Minimum):Minimum,round(~.sum(Sum)/~.sum(Count),2):Averge) |
在A3中执行集群计算,在这里使用的是callx(dfx:x,…;h) 函数,和前面的调用相比,多了reduce表达式x。这里的reduce动作表达式是~~|~,其中~~表示当前执行reduce的结果,~表示当前工作返回的结果,这个表达式表示将每个工作返回的记录合并起来。每个工作返回结果后都会执行reduce动作,计算得到新的~~。执行callx后,从服务器的系统信息输出窗口中,可以看到任务的分配和执行情况如下:
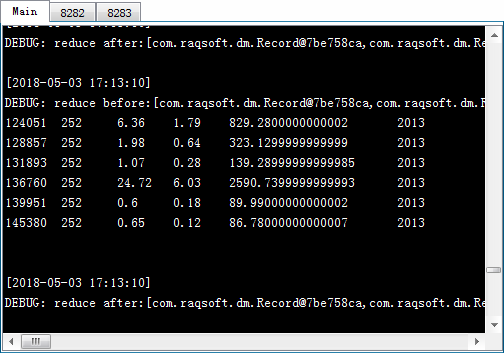
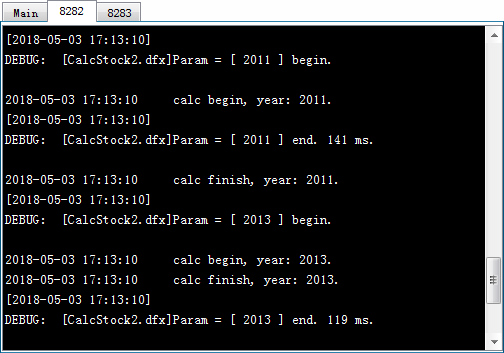
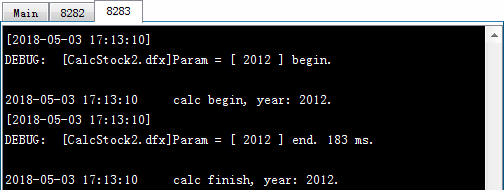
在主进程窗口中,除了工作信息,还输出了reduce动作执行的相关信息。A3中得到的结果如下:
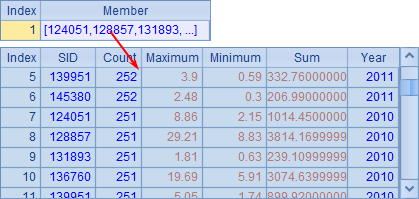
在添加了reduce动作之后,callx的结果是每个分机返回结果的序列。从结果中可以发现,由于是并行计算,单个分机中,各个工作的完成顺序是不定的,如2011年的统计结果有可能排在2010年之前。
A4中将结果分组汇总,计算每支股票的最高价、最低价和均价,计算后结果如下:
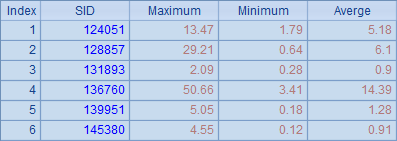
特别的,当仅使用callx执行多线程计算,而不使用集群服务器时,也可以使用reduce表达式,如:
|
|
A |
|
1 |
[2010,2011,2012,2013,2014] |
|
2 |
=callx("CalcStock2.dfx":~~|~,A2;A1) |
|
3 |
=A3.group(SID;~.max(Maximum):Maximum,~.min(Minimum):Minimum,round(~.sum(Sum)/~.sum(Count),2):Averge) |
从A2中使用的表达式可以发现,和集群计算时使用的callx相比,使用多线程计算时,并不使用分机来计算,因此不必指定分机列表h,同时,reduce的动作也不是由各个分机的主线程处理的,所以A2中会直接返回~~的reduce结果,而不会根据分机数返回为序列。A2中结果如下:
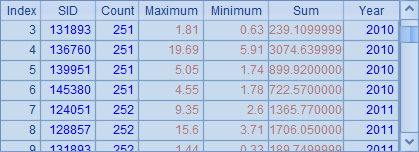
A3中进一步统计的结果则和前例中A4中的结果是一致的。
在集群计算时,如果使用多台分机执行计算,如果分机并不能完成全部工作,那么在分配任务时就有可能会产生错误了。如callx函数中添加@a选项,将子任务严格分配到依次对应的服务器。如再添加一个分机B,主进程是192.168.10.245:8281,该分机共2个分进程,在这个分机上,只存储了StockRecord2010.txt、StockRecord2010.txt和StockRecord2010.txt这3个数据文件。尝试用下面的代码执行集群计算:
|
|
A |
|
1 |
[192.168.10.229:8281,192.168.10.245:8281] |
|
2 |
[2010,2011,2012,2013,2014] |
|
3 |
=callx("CalcStock2.dfx":~~|~,A2;A1) |
|
4 |
=A3.conj().group(SID;~.max(Maximum):Maximum,~.min(Minimum):Minimum,round(~.sum(Sum)/~.sum(Count),2):Averge) |
由于前一个分机A中有3个分进程,分机计算力较高,因此会首先分配3个工作,剩余的2个工作则会分配给分机2去执行,此时,由于分机2上数据文件缺失,执行时会出现错误:
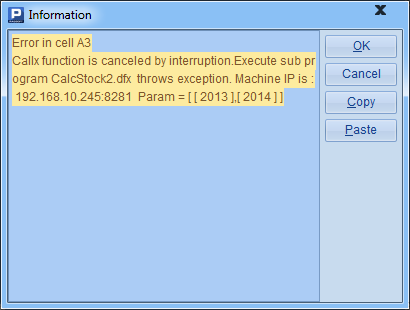
为了避免这样的情况出现,可以在调用callx函数时,在分机序列后,添加分机的作业序号序列,表明每个分机能够执行的作业序号,如:
|
|
A |
|
1 |
[192.168.10.229:8281,192.168.10.245:8281] |
|
2 |
[2010,2011,2012,2013,2014] |
|
3 |
=callx("CalcStock2.dfx":~~|~,A2;A1,[[4,5],[1,2,3]]) |
|
4 |
=A3.conj().group(SID;~.max(Maximum):Maximum,~.min(Minimum):Minimum,round(~.sum(Sum)/~.sum(Count),2):Averge) |
A3中的callx(dfx:x,…;h,s) 函数中,最后添加了参数s,来分配分机A需执行的作业序号是[4,5],而分机B需执行的作业序号是[1,2,3]。执行后,从A3中可以看到任务的分配情况:
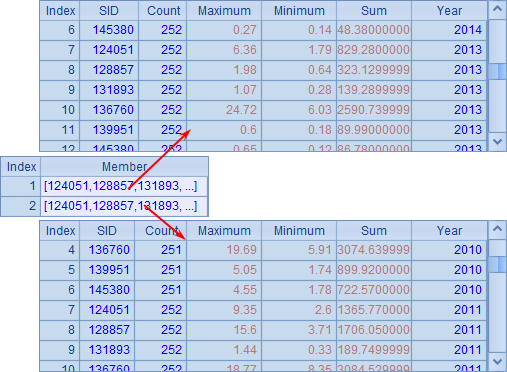
尽管分机A中的分进程较多,任务仍然会按照所指示的序号来分配。注意,此时A3中统计所有数据时,需要先将2个分机返回的结果合并起来。A3中结果如下:
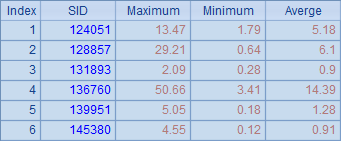
这里得到的结果和用单个分机时的情况是相同的。
从上面的例子可以看到,如果一些工作只能由特定的分机计算,会带来一些麻烦。如果某个服务器出现故障,甚至会使得主任务无法完成。
用 fork 语句执行集群计算
在8.1多线程中,我们介绍了fork语句的使用,可以多线程执行一段代码。实际上,上一小节中使用的callx就是在集群中的各个服务器端,执行某个dfx文件中的代码。
所以,callx的计算,也可以用fork来处理,如:
|
|
A |
B |
C |
|
1 |
[192.168.10.229:8281] |
|
|
|
2 |
[124051,128857,131893,136760,139951,145380] |
|
|
|
3 |
fork A2;A1 |
>output@t("calc begin, SID="+string(A3) +". ") |
|
|
4 |
|
=file("D:/files/txt/StockRecord.txt").import@t() |
=B4.select(SID==A3) |
|
5 |
|
=C4.count() |
=C4.max(Closing) |
|
6 |
|
=C4.min(Closing) |
=round(C4.avg(Closing),2) |
|
7 |
|
>output@t("calc finish, SID="+string(A3) +". ") |
return B5,C5,B6,C6 |
|
8 |
=A3.new(A2(#):SID,~(1):Count,~(2):Maximum,~(3):Minimum,~(4):Average) |
|
|
这其实相当于把集群计算中需要重复执行的子网格直接写入了代码块中,可以不必维护多个dfx文件。使用多个分机时,如果需要指定分机,可以在fork函数的最后添加分机执行的工作序号序列s,如fork A2;A1:[[4,5],[1,2,3]]。A3中,收集每个工作返回的结果如下:
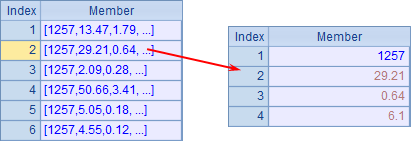
在返回结果序列时,A3中的结果和参数的顺序是一致的,A8将集群结果整理后,得到下表:
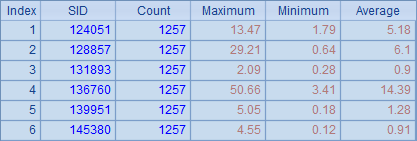
在fork的使用模式里,也可以添加reduce动作,如:
|
|
A |
B |
C |
|
1 |
[192.168.10.229:8281] |
|
|
|
2 |
[124051,128857,131893,136760,139951,145380] |
|
|
|
3 |
fork A2;A1 |
>output@t("calc begin, SID="+string(A3) +". ") |
|
|
4 |
|
=file("D:/files/txt/StockRecord.txt").import@t() |
=B4.select(SID==A3) |
|
5 |
|
=C4.count() |
=C4.max(Closing) |
|
6 |
|
=C4.min(Closing) |
=round(C4.avg(Closing),2) |
|
7 |
|
>output@t("calc finish, SID="+string(A3) +". ") |
return A3,B5,C5,B6,C6 |
|
8 |
reduce |
if(ift(~~),~~.record(~),create(SID, Count, Maximum, Minimum, Average ).record(~~).record(~)) |
|
在reduce代码块中,添加了reduce动作的函数,在第一次reduce动作时,新建结果序表,并将~~中的首个工作结果以及~返回的第二个工作结果数据填入,之后的reduce动作则相应在结果序表中添加记录。执行后,在A3中可以看到执行集群计算的结果:
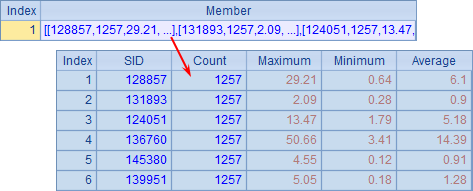
这里只使用了一台分机,其返回的序表即为所需的统计结果。在使用分机的reduce处理结果时,记录的顺序就无法确定了,会由各个工作的完成顺序来决定,因此这里的SID需由各个工作直接返回。
用集群计算处理大运算量任务
前面的例子是用集群计算来处理大数据量的运算,在每个子任务中只处理部分数据,从而更充分地利用有限的内存。还有一种情况,是需要完成大运算量的任务,此时也可以使用集群计算,将运算分配到多个服务器中执行,在主程序中汇总结果。
如下面的子程序CalcPi.dfx:
|
|
A |
B |
C |
|
1 |
1000000 |
0 |
>output@t("Task "+ string(arg1)+ " start...") |
|
2 |
for A1 |
=rand() |
=rand() |
|
3 |
|
=B2*B2+C2*C2 |
|
|
4 |
|
if B3<1 |
>B1=B1+1 |
|
5 |
>output@t("Task "+ string(arg1)+ " finish.") |
return B1 |
|
参数arg1用来记录任务序号:
这是一个用概率来估算圆周率π的程序。先来看下面的图:

在边长为1的正方形中有1/4个圆,正方形的面积为1,扇形的面积为π/4。那么正方形中的任意1个点落在扇形内的概率就是它们的面积比,也就是π/4。在子程序中,随机生成1,000,000个横纵坐标在[0,1)区间内的点,考察它们距原点的距离,并记录下在扇形内的点的个数,以此来估算π。
主程序如下:
|
|
A |
B |
|
1 |
[192.168.10.229:8281] |
20 |
|
2 |
=callx("CalcPi.dfx",to(B1);A1) |
=A2.sum()*4/(1000000d*B1) |
通过调用20次子程序,用集群计算将20,000,000个点的计算分配到服务器完成,仍然使用前面的服务器。可以在各个服务器的系统信息输出窗口中,看到任务的分配和执行情况:
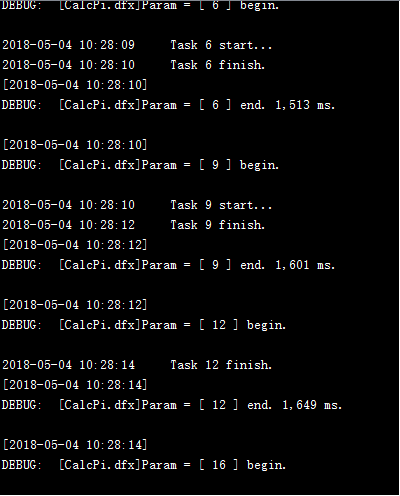
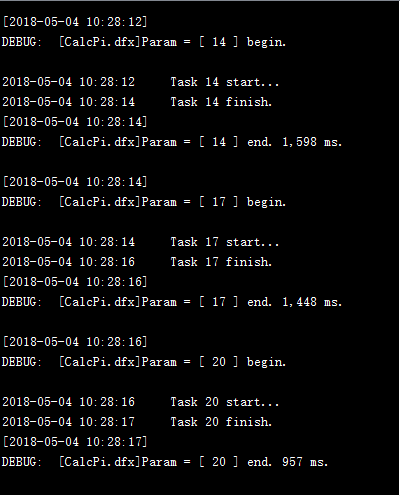
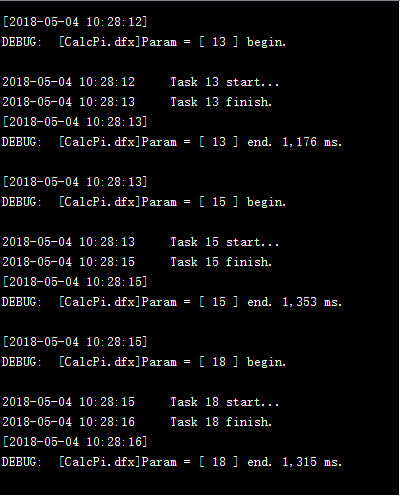
如果工作总数超过了分机容纳任务总数,当前面任务分配至各个分机进程均已占满时,后面的任务需要等待有进程空闲下来再分配。此时进程出现空闲,任务就会被分配到哪个服务器,每次分配的情况是有可能变化的。各个工作的计算过程各自独立,因此后分配的工作也有可能会先完成,但是并不会影响并行计算结果。
在B2中计算出π的近似值如下,由于是用概率随机计算的,每次获得的结果均有差别:
![]()