集群组表
在10.1服务器 中,介绍了如何使用分机实现集群计算,组表可以通过分机访问,作为集群组表使用。首先,需要把组表文件上传到服务器,在集算器安装目录的esProc\bin路径下,运行datastore.exe,打开数据存储管理器,将组表文件上传到分机中指定的分区:
在这里先将文件上传到各个分机的0分区中,每个分机的文件分区的磁盘路径可以在服务器配置中设置,0分区默认的存储位置是D:/0。此时即可通过访问分机读取组表文件:
|
|
A |
|
1 |
[192.168.10.229:8281] |
|
2 |
=file@0("employees.ctx",A1) |
|
3 |
=A2.create() |
|
4 |
=A3.cursor().fetch() |
|
5 |
=A3.cursor() |
|
6 |
=A5.groups(Dept;count(~):Count) |
在A2中,使用函数file(fn,h) 从服务器列表h中读取组表文件fn,打开集群文件。这个例子中仅使用了单个分机上的组表文件,由于文件存储在0分区,在file函数中添加了@0选项,A2中得到结果如下:
![]()
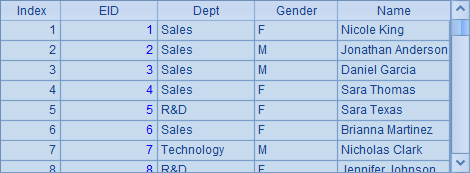
在A3中用T.create() 打开组表的基表,此时的组表称为集群组表,集群组表的实表称为集群实表。在集群组表中,可以用T.attach(T') 函数取出附表T'。集群表是只读的,在计算时和本地组表是相同的,根据集群文件的不同,集群表相应称为分布表和复写表。A4中用T'.cursor()由集群组表的基表T'生成游标,并从游标中取得数据如下:
在分机中,可以查看窗口信息如下:
在使用集群组表时,分机中只有主进程参与提供文件服务,会在访问集群文件时输出信息。
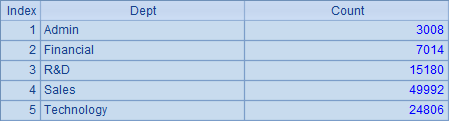
集群组表生成的游标也可以执行cs.join(),cs.groupx(),cs.groups() 等各类计算。如A6中用cs.groups() 得到分组聚合的结果如下:
与组表类似,使用集群组表时,也可以使用集群内表,在内存中使用集群表:
|
|
A |
|
1 |
[192.168.10.229:8281] |
|
2 |
=file@n("D:/file/dw/employees.ctx",A1) |
|
3 |
=A2.create().attach(etable) |
|
4 |
=A3.memory(;right(Name,6)=="Garcia") |
|
5 |
=A4.dup() |
|
6 |
=A5(4) |
A2中打开集群文件时,添加了@n选项,此时的文件并不是从分机对应的分区中查找的,而是直接根据文件名获取。与生成本地组表的内表类似,在A4中用memory() 函数生成集群内表,A4中可以查看到集群内表的结果如下:
![]()
集群内表并不能直接作为序表使用,可以用T.dup() 函数,将集群内表T转换为本地内表,如A5中结果如下:
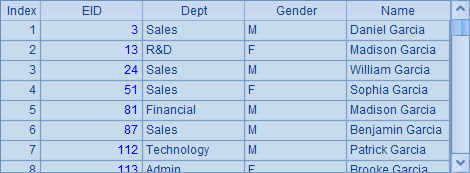
A5中即为普通内表了。普通的内表T也可以用T.dup(h) 函数转换为集群内表。
实际上,在上面的分区示意图中可以看到,在另一台分机192.168.10.245:8281上,也同样在0区存储了employees.ctx,此时,也可以同时使用两台分机执行查询,如:
|
|
A |
|
1 |
[192.168.10.245:8281, 192.168.10.229:8281] |
|
2 |
=file@0("employees.ctx", A1) |
|
3 |
=A2.create() |
|
4 |
=A3.cursor@z() |
|
5 |
=A4.fetch() |
和前面的使用不同的是,A2中打开集群文件时使用了多个分机。而在A4中生成游标时,添加了@z选项,此时读取相同的组表文件时,将会在分机间拆分处理,但游标的使用和单分机时是相同的。A5中得到结果如下:
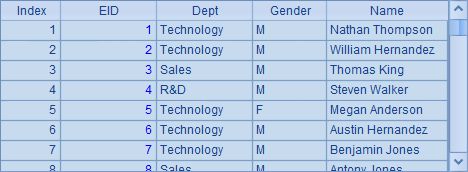
在上面的例子中,如果集群文件由各个分机上相同的文件构成,称为复写文件,各个分机上的文件必须完全相同。如果集群文件由多个分机上不同的文件构成,称为分布文件,这种情况下,各个分机上的文件名称必须是相同的。下面我们来看在集群中如何使用分布文件,为此需要先构建分布文件,它们会存储着同一个表中的不同数据,如:
|
|
A |
B |
|
1 |
=file("D:/file/dw/employees.ctx") |
=file("D:/file/dw/orders.ctx") |
|
2 |
=A1.create() |
=B1.create() |
|
3 |
=A2.attach(stable) |
=B2.attach(otable) |
|
4 |
=A3.cursor(EID,Name, OCount).fetch() |
=B3.cursor(Date,EID,Amount).sortx(Date,EID).fetch() |
|
5 |
=file("D:/file/dw/1/salespart.ctx") |
=file("D:/file/dw/1/orderpart.ctx") |
|
6 |
=A5.create(#EID, Name, OCount) |
=B5.create(#Date,#EID,Amount) |
|
7 |
>A6.append(A4.cursor(1:2)) |
>B6.append(B4.cursor(1:2)) |
|
8 |
=file("D:/file/dw/2/salespart.ctx") |
=file("D:/file/dw/2/orderpart.ctx") |
|
9 |
=A8.create(#EID, Name, OCount) |
=B8.create(#Date,#EID,Amount) |
|
10 |
>A9.append(A4.cursor(2:2)) |
>B9.append(B4.cursor(2:2)) |
A4中从组表employees.ctx的实表stable中获取销售员数据如下:
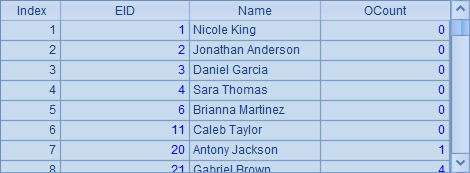
B4中,从组表orders.ctx的实表otable中取得订单数据,这里的数据是先按Date排序,再按EID排序,数据如下:
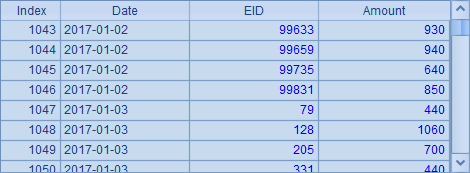
在A5~A10的代码中,将销售员数据拆分,存入了两个同样命名为salespart.ctx的组表文件,这两个文件置于不同目录中,准备将它们用作分布文件。
在B7~B16的代码中,将订单数据拆分,存入了不同路径中两个文件名同为orderpart.ctx的组表中。
这次在同一台电脑启动两个分机A(192.168.10.229:8281)和B (192.168.10.229:8291),使用Data Store工具将这些文件分别上传到分机中。其中分机A存储目录D:/file/dw/1中的前一半数据,分区1中存储salespart.ctx,分区0中存储orderpart.ctx;分机B存储目录D:/file/dw/2中的后一半数据,分区2中存储salespart.ctx,分区0中存储orderpart.ctx:

此时来看如何使用分布式集群组表:
|
|
A |
B |
C |
|
1 |
192.168.10.229:8281 |
192.168.10.229:8291 |
[192.168.10.229:8281, 192.168.10.229:8291] |
|
2 |
=file@0("orderpart.ctx", A1) |
=file@0("orderpart.ctx", B1) |
=file@0z("orderpart.ctx", C1) |
|
3 |
=A2.create() |
=B2.create() |
=C2.create() |
|
4 |
=A3.cursor().fetch() |
=B3.cursor().fetch() |
=C3.cursor().fetch() |
|
5 |
|
|
|
|
6 |
=file@z("salespart.ctx", A1) |
=file("D:/file/dw/2/salespart.ctx") |
=file@z("salespart.ctx", C1) |
|
7 |
=A6.create() |
=B6.create() |
=C6.create() |
|
8 |
=A7.cursor().fetch() |
=B7.cursor().fetch() |
=C7.cursor().fetch() |
在两个分机上,orderpart.ctx都存储在0分区上,在A2和B2中使用file@0(fn, h) 函数,指明集群文件所在的分机,即可打开对应分机中0分区中的文件。在A3和B3中取出对应的集群实表,在A4和B4中结果如下:

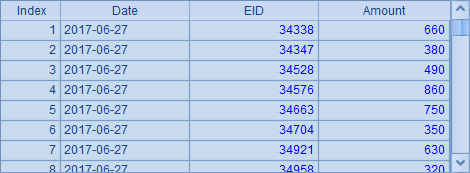
可以看到两个分机上存储文件的不同,分机A上只存储了前一半订单记录,分机B上只存储了后一半订单记录。两个部分的数据是相邻的。
C2中使用file@0z(fn, h) 函数打开分布集群文件,@0z选项表示由分机列表h中所有分机0区的文件构成分布文件。C3中打开集群实表后,C4中取出数据如下:
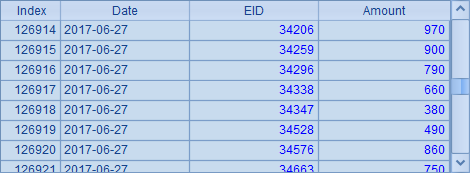
可以看到,集群表中能够获得各个分机文件中的数据。
对于存储在其它分区中的文件,就只能使用file@z(fn, h) 函数打开了,但是使用选项时,对文件存储的分区是有要求的,在分机列表h中,分布式文件必须存储在第一台分机的1区,第2台分机的2区,……因此,在A6中只指定了1台分机时,会打开分机1区中的文件,A8中返回实表中数据如下:
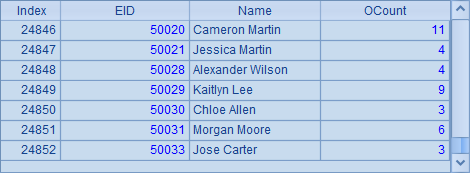
对于分机B中的文件userpart.ctx,由于它存储在分区2中,因此不能单独读取这个文件。B6中打开了本地的组表文件,在B8中取出实表中数据如下:
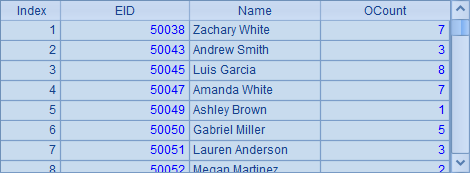
可以看到,分机A中只存储了前24852条数据,而分机B则存储的是后面的销售员数据,两个部分的数据是相邻的。
在C6中,由不同分机不同分区上的分布文件构成集群文件,在C8中取出实表中数据如下:
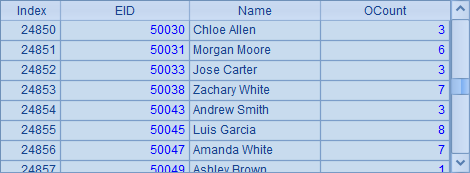
从集群组表中,取出的就是全部的数据了。
从上面的两个分布表userpart.ctx和scorepart.ctx中的数据可以发现,它们在不同分机上存储的数据是不匹配的,如分机A中,userpart.ctx中存储了前一半用户的信息,而scorepart.ctx中存储的是所有用户前两次测试的数据。这样,如果需要将两个分布表中的数据关联起来计算,需要用cs.sortx(…;x) 或cs.groupx(…;x) 与集群游标x同分布处理,如:
|
|
A |
B |
|
1 |
[192.168.10.229:8281, 192.168.10.229:8291] |
|
|
2 |
=file@z("salespart.ctx", A1) |
=file@0z("orderpart.ctx", A1) |
|
3 |
=A2.create() |
=B2.create() |
|
4 |
=A3.cursor() |
=B3.cursor() |
|
5 |
=B4.sortx(EID; A4) |
=joinx(A4:s,EID;A5:o,EID) |
|
6 |
=B5.new(s.EID:EID,s.Name:Name,o.Date:Date,o.Amount:Amount) |
=A6.fetch() |
A4和B4中分别用salespart.ctx和orderpart.ctx构成分布表的集群游标,在A5中,将B4中测试数据的排序,将排序的结果按照用户数据来同分布处理,生成与用户数据同分布的游标。在B5中,用join函数将两个同分布的游标连接,并在A6中生成需要整理的结果。B6中取出数据如下:
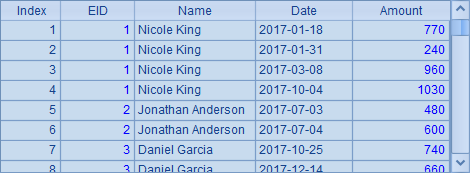
可以发现,不同分步的集群组表,能够正确匹配,返回所需要的计算结果了。