使用常见数据
在做数据分析处理工作时,首先需要读入原始数据,而最常用的数据就来自文本文件或者数据库。在集算器中,可以很快捷地读入文本或者数据库中的数据。
使用文本数据
集算器可以将文本文件中的数据读入为一个序表,如:文本文件employee.txt中保存了员工的信息,如下:
|
EID |
NAME |
SURNAME |
GENDER |
STATE |
BIRTHDAY |
HIREDATE |
DEPT |
SALARY |
|
1 |
Rebecca |
Moore |
F |
California |
1974-11-20 |
2005-03-11 |
R&D |
7000 |
|
2 |
Ashley |
Wilson |
F |
New York |
1980-07-19 |
2008-03-16 |
Finance |
11000 |
|
3 |
Rachel |
Johnson |
F |
New Mexico |
1970-12-17 |
2010-12-01 |
Sales |
9000 |
|
4 |
Emily |
Smith |
F |
Texas |
1985-03-07 |
2006-08-15 |
HR |
7000 |
|
5 |
Ashley |
Smith |
F |
Texas |
1975-05-13 |
2004-07-30 |
R&D |
16000 |
|
6 |
Matthew |
Johnson |
M |
California |
1984-07-07 |
2005-07-07 |
Sales |
11000 |
|
7 |
Alexis |
Smith |
F |
Illinois |
1972-08-16 |
2002-08-16 |
Sales |
9000 |
|
8 |
Megan |
Wilson |
F |
California |
1979-04-19 |
2004-04-19 |
Marketing |
11000 |
|
9 |
Victoria |
Davis |
F |
Texas |
1983-12-07 |
2009-12-07 |
HR |
3000 |
|
… |
|
|
|
|
|
|
|
|
在集算器中,读取文件中的数据,需要使用import函数:
|
|
A |
|
1 |
=file("employee.txt ") |
|
2 |
=A1.import@t() |
|
3 |
=A1.import() |
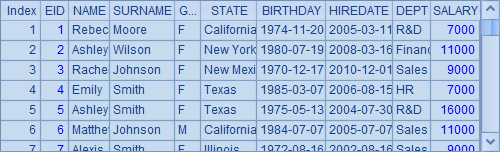
A2中,import函数使用了@t选项,读入数据时,会将这个文本文件的第一行设置为序表的列名,A2中数据如下:
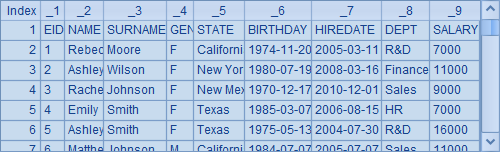
可以看一下不使用@t选项的情况,A3中的序表如下:
使用数据库中的数据
集算器可以通过JDBC访问各类数据库,在Tool菜单项中,点击Datasource Connection可以查看数据源管理器:
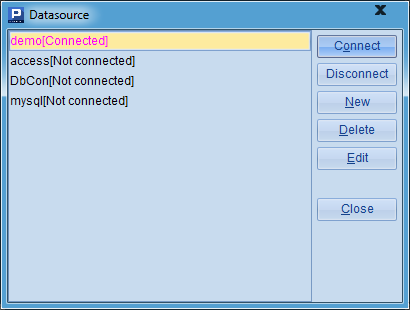
在数据源管理器中,可以连接或者断开某个数据源,也可以在这里配置需要连接的数据库。其中demo是集算器自带的数据源,可以执行安装目录下的esProc\bin\startDataBase.bat启动。数据源连接后,就可以直接访问数据库,用SQL取出表中的数据:
|
|
A |
|
1 |
=demo.query("select * from CITIES") |
|
2 |
$select * from CITIES |
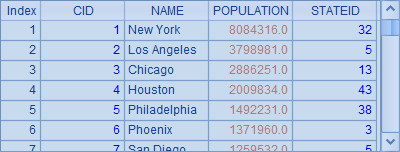
用query函数可以获得SQL执行的结果集,并读取为序表,如A1中的示例。当连接了数据库的时候,也可以在$符号后面直接使用SQL语句,如A2。A1和A2中的结果是相同的,如下:
如果未在数据源管理器中连接数据源,也可以用connect函数连接,此时数据读取后,应该用close将数据库连接关闭:
|
|
A |
|
1 |
=connect("demo") |
|
2 |
=A1.query("select * from CITIES") |
|
3 |
>A1.close() |
A2中读出的城市信息序表,与上面的方法是相同的。