组表的访问
组表保存到文件后,可直接用f.create() 函数打开,这里不需再指定参数,如:
|
|
A |
B |
|
1 |
=file("D:/file/dw/employees.ctx") |
|
|
2 |
=A1.create() |
=A2.cursor().fetch() |
|
3 |
=A2.attach(stable) |
=A3.cursor().fetch() |
|
4 |
|
=A3.cursor(EID,Dept,Gender,Name,OCount,OAmount).fetch() |
在A2中,使用无参数的create函数打开组表的基表,在A3中,仅指定附表的名称,用T.attach函数打开实表。在B2中查询出组表基表中数据如下:
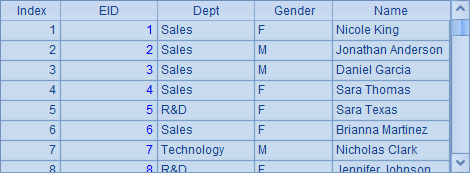
这里获得的数据和前面填入组表中的数据是相同的。
B3中查询出实表stable中数据如下:
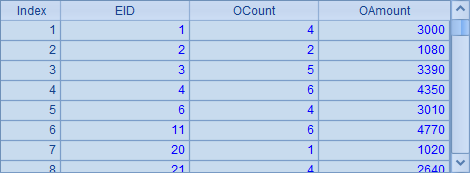
从附表中查询的数据也可以包括主表中的字段,如B4中生成游标时,同时取出了主表中的字段,结果如下:
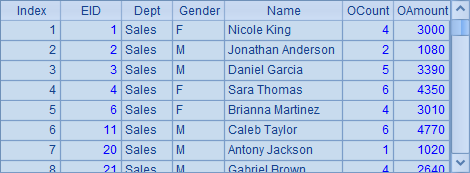
在上面的例子中从实表中查询数据时,使用了T'.cursor() 函数,实际上,在使用函数T'.cursor(C1, C2…; w)从实表T'中查询数据时,还可以设置从实表中选取的字段C1, C2…或者查询条件w,如:
|
|
A |
B |
|
1 |
=file("D:/file/dw/employees.ctx") |
|
|
2 |
=A1.create() |
=A2.attach(stable) |
|
3 |
=A2.cursor(EID,Name,Dept) |
=A3.fetch() |
|
4 |
=A2.cursor(;right(Name,1)=="e") |
=A4.fetch() |
|
5 |
=B2.cursor(EID,Name,OCount,OAmount;OAmount>5000) |
=A5.fetch() |
A3中仅从组表的基表中取出部分字段,B3中fetch获得的结果如下:
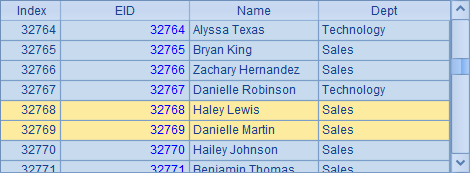
A4中设置了查询姓名最后一个字母为e的员工数据,B4中获得的结果如下:
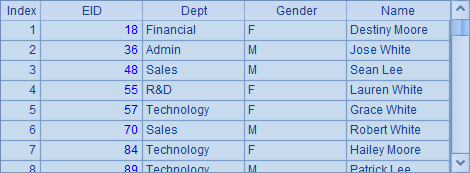
A5中从实表stable中取出OAmount超过5000的销售员数据,B5中获得的结果如下:

当组表中的数据较多时,也可以分段读取数据,此时首先需要将组表分段存储。其实,组表默认情况下总是会分段存储的,如果不需分段可以在create函数中添加@u选项。但是,组表中实表分段的结果并不一定是我们需要的情况,因此在需要分段存储时,最好指明分段依据的字段。下面来了解实表中数据分段存储和分段读取的情况:
|
|
A |
B |
|
1 |
=file("D:/file/dw/employees.ctx") |
=A1.create() |
|
2 |
=B1.attach(stable) |
|
|
3 |
=file("D:/file/dw/orders.ctx") |
=A3.create() |
|
4 |
=B3.attach(otable) |
|
|
5 |
=A2.cursor(;;1:3).fetch() |
=A2.cursor(;;2:3).fetch() |
|
6 |
=A4.cursor(;;1:3).fetch() |
=A4.cursor(;;2:3).fetch() |
A2中从组表文件employees.ctx中取出销售员实表stable,A5和B5中,从销售员实表中分段取数,都分为3段,但分别取出第1段和第2段,结果分别如下:
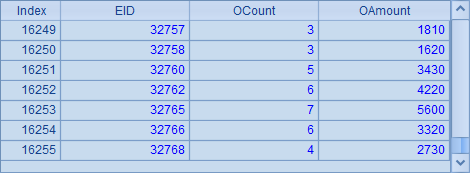
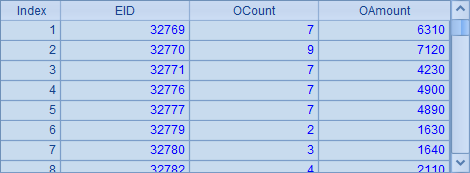
和上一个例子中,A4中的员工数据对比可以发现,第1段最后的销售员序号32768,和第2端最初的销售员序号32769是相邻的销售人员序号,这说明,在分段读取时,数据能全部被遍历,同时又不会重复被读取。
A4打开组表文件orders.ctx中的订单实表otable,A6和B6中,从订单实表中分段取数,同样分为3段,并分别取出第1段和第2段,结果分别如下:
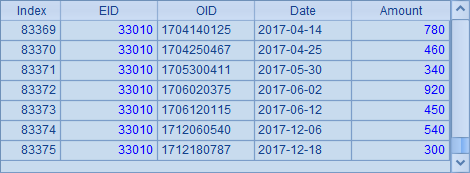
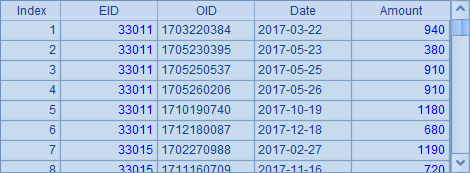
首先,因为otable中数据更多,所以分段读取后,每段读取到的记录数量也更多。其次,由于在存储orders.ctx时,设定了按EID分段,因此分段时会把相同销售人员的订单分在同一段,保证第1段末尾与第2段开头的记录属于不同的销售人员。同时,与B5和B6中的数据对比可以发现,在使用不同的组表文件时,由于数据本身存在差异,分段的情况并不一定相同,如销售员数据的第2段首条记录的EID为32769,而订单数据第2段的首条记录的EID为33011,分段情况是不同的。
在使用多个组表中的实表时,需要避免分段的不同步,此时,可以使用多路游标进行同步。如:
|
|
A |
B |
|
1 |
=file("D:/file/dw/employees.ctx") |
=file("D:/file/dw/orders.ctx") |
|
2 |
=A1.create() |
=B1.create() |
|
3 |
=A2.attach(stable) |
=B2.attach(otable) |
|
4 |
=A3.cursor@m(;;3) |
=B3.cursor(;;A4) |
|
5 |
=joinx(A4:s,EID;B4:o,EID) |
=A5.fetch() |
|
6 |
=A3.cursor@m(;;3) |
=B3.cursor(;;A6) |
|
7 |
=joinx(A6:s,EID;B6:o,EID) |
=A7.groups(s.EID:EID;count(~):Count, sum(o.Amount):Sum) |
A3和B3中,分别在两个不同的组表中,读出实表stable和实表otable。在A4中,用函数T.cursor@m(;;n) 将实表stable分为n段生成多路游标,在B4中用实表otable根据A4中的多路游标同步分段。执行同步分段后,在A5中将A4和B4中的游标用joinx函数将同步的多路游标连接起来,在B5中可以看到连接的结果:
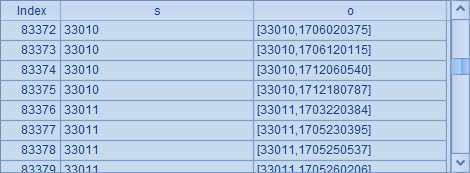
从结果中可以看到,原本两个分段效果不同的游标,经过同步分段后,能够正确匹配。
在B7中,重新生成多路游标的连接,并计算出每个销售员的订单总数和销售总数,结果如下:
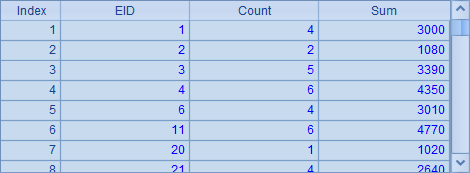
将结果与前面stable中的OCount和OAmount对照,可以确认连接的结果是正确的。
在实表中,可以根据条件为其生成索引,如果使用索引来执行查询,效率会明显提高。如:
|
|
A |
B |
|
1 |
=file("D:/file/dw/employees.ctx") |
=A1.create() |
|
2 |
=B1.cursor().fetch() |
|
|
3 |
|
=now() |
|
4 |
=B1.cursor(;[8136,11247,83372,264,8223,826,32758,1341,6255,1983].contain(EID)) |
=A4.fetch() |
|
5 |
|
=interval@ms(B3, now()) |
|
6 |
>B1.index(idx, [8136,11247,83372,264,8223, 826,32758,1341,6255,1983].contain(EID);EID) |
=now() |
|
7 |
=B1.icursor(;[8136,11247,83372,264,8223, 826,32758,1341,6255,1983].contain(EID),idx) |
=A7.fetch() |
|
8 |
|
=interval@ms(B6, now()) |
第1、2行打开组表employees.ctx中的基表员工实表。在第4行,直接从实表中查询10条记录,B4中得到结果如下:
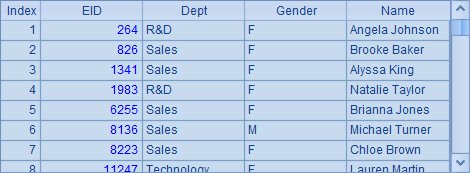
在A6中,用函数T.index(I, w; C,…) 为实表生成索引,A6中将索引命名为idx,并根据键EID生成。执行后,索引文件将自动生成,文件名自动处理。在A7中使用T.icursor(C,…; w, I) 函数查询时,可以根据索引文件来执行。B7中得到的结果和B4中是相同的。调用T.index(I, w; C,…) 函数时如果未设字段C,…,则会删除实表T的索引I,如果无参数I,则会删除实表T的所有索引。
B5和B8中分别计算出两种情况下查询100条记录的耗时如下:
![]()
![]()
可以发现,使用索引时,查询效率会更高。另外,如果在组表是按行存储的,那么在使用索引查询时,能够获得更好的性能。