子程序
代码复用在程序设计中可以使代码更为简洁高效,集算器中可以通过循环实现最基本的代码复用。另外还可以通过子程序调用和跨网格程序调用,用子程序或者网格代码实现模块化的功能。在这里,我们来讲述如何在集算器中使用子程序调用和跨网格调用。
子程序调用
子程序是以语句func为主格的代码块,结果需要用return语句返回。在表达式中使用func(C, xi,…) 函数,可以调用C单元格代码块中的子程序,使用的参数是xi,…。如:
|
|
A |
B |
|
1 |
func |
/create an ID |
|
2 |
|
>id="" |
|
3 |
|
>A1.run(id=id+char(65+rand(26))) |
|
4 |
|
return id |
|
5 |
=func(A1,rand(3)+3) |
|
在A1为主格的代码块,即第1~4行中,根据所给的字符长度,随机生成一个大写字母构成的ID。其中B2将网格变量id设为空字符串。B3根据子程序主格中获得的字符长度,执行循环,每次在id中随机添加一个大写字母。在每次执行前,需要先将使用的网格参数id初始化。在B4中,用return语句将网格变量id的值返回。在A5中,用func函数调用子程序,在=func(A1,rand(3)+3)中,A1表示所调用子程序的主格,rand(3)+3计算出一个3~5的随机整数作为参数,传递给子程序执行计算。这样A5中可以得到一个由3~5个随机字符构成的字符串,如:
![]()
在调用子程序时,func命令中的参数会抄入子程序的主格。
和其它程序中的子程序一样,集算器中的子程序往往是需要重复使用的,如:
|
|
A |
B |
|
1 |
=5.(func(A2,2)) |
=10.(func(A2,rand(3)+3)) |
|
2 |
func |
/create an ID |
|
3 |
|
>id="" |
|
4 |
|
>A2.run(id=id+char(65+rand(26))) |
|
5 |
|
return id |
在A1中,随机生成5个由两个字母构成的字符串,作为产品名称的缩写。B1中,随机生成10个由3~5个字符构成的字符串,作为客户名称,A1和B1中的结果如下:

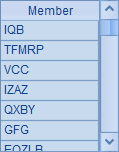
从这两个例子中的代码中可以看到,子程序可以被网格中任何地方的函数调用。实际上,在网格运行时,只有当子程序被调用时,子程序所在的代码块才会被执行。
子程序与循环结构的语句,都使用在代码块中。但是,循环结构的语句只在执行主格的循环时执行,子程序则可以在任何格子中用func函数调用。当子程序未被调用时,子程序区块中的代码不会被执行。当子程序被调用时,执行到区块结束,或者到第一个return语句会结束执行并返回。如果需要返回多个结果,如何处理呢?看看下面的例子:
|
|
A |
B |
C |
|
1 |
=create(Product,Customer) |
0 |
|
|
2 |
func |
/create an ID |
|
|
3 |
|
>id="" |
>A2.run(id=id+char(65+rand(26))) |
|
4 |
|
return id |
|
|
5 |
func |
|
|
|
6 |
|
return [A7(A5),B7(B5)] |
|
|
7 |
=5.(func(A2,2)) |
=10.(func(A2,rand(3)+3)) |
|
|
8 |
for 100 |
=func(A5,rand(5)+1,rand(10)+1) |
>A1.insert(0,B8(1),B8(2)) |
在A5为主格的子程序中,根据参数得到了1个产品名和1个客户名,在B6中将结果构成序列返回。另外B8调用子程序时,随机生成1个产品序号和1个客户序号,作为参数输入子程序。当调用子程序的参数多于1个时,会从主格起向右填充。
在B8中,可以看到最后一次调用子程序时返回的结果:
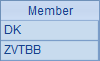
在C8中使用结果时,再分别从序列中取出数据。第8行的程序随机生成100条数据插入A1中的序表,记录由产品名与客户名构成。执行后,A1中序表如下:
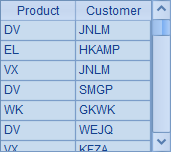
子程序不一定有返回值,当子程序代码块中没有return语句时,调用时会顺次执行到代码块结束为止。如:
|
|
A |
B |
C |
|
1 |
=create(OID,Product,Customer,Amount) |
0 |
|
|
2 |
func |
/create an ID |
|
|
3 |
|
>id="" |
>A2.run(id=id+char(65+rand(26))) |
|
4 |
|
return id |
|
|
5 |
func |
|
/add a record |
|
6 |
|
>B1=B1+1 |
=(rand(1000)+1)*100 |
|
7 |
|
>A1.insert(0,B1,A5,B5,C6) |
|
|
8 |
=5.(func(A2,2)) |
=10.(func(A2,rand(3)+3)) |
|
|
9 |
for 100 |
=A8(rand(5)+1) |
=B8(rand(10)+1) |
|
10 |
|
>func(A5,B9,C9) |
|
A2中的子程序和前面例子中的相同。A5中的子程序并没有return语句,此时子程序没有返回值,每次运行时只是在A1的序表中添加一条记录。因此,在B10调用A5中的子程序时,可以用>开头,子程序的调用会执行到A5的代码块结束为止。
在A9中,循环生成100条测试数据,填入A1的序表中,结果如下:
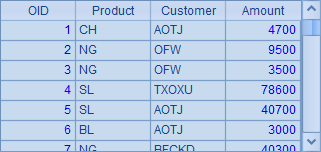
在子程序中,可以使用递归调用自身。如:
|
|
A |
B |
C |
|
1 |
func |
|
|
|
2 |
|
if A1<=0 |
return 1 |
|
3 |
|
else |
>A5=A5+string(A1)+";" |
|
4 |
|
|
return A1*func(A1,A1-1) |
|
5 |
="" |
|
|
|
6 |
=func(A1,12) |
|
|
A1的子程序中,根据传入的数据判断,当其大于0时,在C4中递归调用自身,计算阶乘。A6中计算12的阶乘如下:
![]()
在子程序被调用时,将每次使用的参数记录在了A5的字符串中,可以从中看到递归调用的过程:
![]()
使用递归调用,可以解决一些比较复杂的问题,如:
|
|
A |
B |
C |
|
1 |
func |
|
|
|
2 |
|
=A1\B1 |
=A1%B1 |
|
3 |
|
if C2==0 |
return B1 |
|
4 |
|
else |
return func(A1,B1,C2) |
|
5 |
=func(A1,4557,5115) |
|
|
这个例子中用欧几里得算法求解2个数的最大公约数。A5中得到4557与5115的最大公约数如下:
![]()
在子程序中,也可以不写return来返回结果,此时,将返回子程序区段中,最后一个以=开头的计算格的值。如:
|
|
A |
B |
C |
|
1 |
func |
/create an ID |
|
|
2 |
|
>id="" |
>A1.run(id=id+char(65+rand(26))) |
|
3 |
|
=id |
Test |
|
4 |
=5.(func(A1,2)) |
=10.(func(A1,rand(3)+3)) |
|
在这里,A1的子程序中,并没有return语句。在这时,返回的结果是子程序区段中,最后一个以=开头的计算格的值,也就是B3的格值,而不是常数格C3。因此,返回的结果相当于再B3中用return id。此时,A4中的结果仍然是随机生成5个由两个字母构成的字符串,B4中也仍然是随机生成10个由3~5个字符构成的字符串。
跨网格调用
除了可以调用子程序之外,在集算器中,还可以进行跨网格调用,即在程序中用call函数运行其它网格中的程序,或是使用其它网格中的计算结果。在这种时候,相当于将整个网格作为一个子程序来执行,在网格中需要用return来返回计算结果,当返回后结束所调用程序的执行,释放资源。例如,网格D:\files\createID.dfx如下:
|
|
A |
B |
|
1 |
/create an ID |
|
|
2 |
|
>size.run(A2=A2+char(65+rand(26))) |
|
3 |
return A2 |
|
在这里,B2循环在A2中添加字符,随机生成ID,并用return语句返回。与调用子程序时类似,在跨网格调用时,也可以不使用return语句,此时将返回最后一个以=开头的计算格的值。如可以将A3中的代码改为=A2,结果是一样的。需要注意到,在B2中用到了参数size,这是一个网格参数,需要在菜单栏中点击Program>Parameter设置:
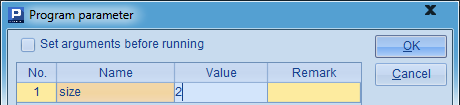
跨网格调用时,如果需要使用参数,需要通过所调用的dfx文件中使用的网格参数传入。用call函数跨网格调用的方法,与子程序调用类似:
|
|
A |
|
1 |
=call("D:\\files\\createID.dfx",rand(3)+3) |
|
2 |
=call("createID.dfx",rand(3)+3) |
使用的参数同样写在后面,所不同的是,A2调用网格程序时,直接指定所调用的dfx文件名。A1中的写法,需要注意\用在字符串表达式中是转义符,需要在它前面再添加一个\来表示字符本身。A1和A2调用前面的dfx文件,随机生成3~5个字符的ID,如下:
![]()
![]()
如果使用A2中的写法,需要保证dfx文件置于集算器的主路径或者寻址路径中。在菜单栏中点击Tool>Options,在选项设定的Environment页面中,可以设定主路径和寻址路径,如:
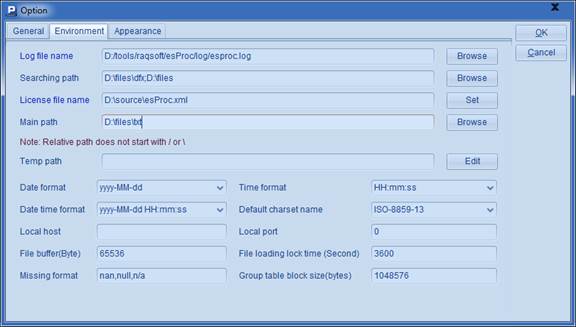
在上面的设置中,dfx文件置于主路径Main Path中,或者寻址路径Searching Path的任何一个目录中,用call函数调用时,都可以只用文件名,而不用写全路径。
如果是被集成使用时,则需要在配置文件raqsoftConfig.xml中,设置主路径与寻址路径:
<Esproc>
<dfxPathList>
<dfxPath>E:\tools\raqsoft\esProc\demo\Case\Structural</dfxPath>
<dfxPath>D:\files\txt</dfxPath>
</dfxPathList>
<mainPath>D:\files\demo</mainPath>
</Esproc>
在跨网格调用时,也可以使用多个参数,或者返回多个结果。如D:\files\findNames.dfx如下:
|
|
A |
B |
|
1 |
/find a PNAME and a CNAME |
|
|
2 |
=rand(PNames.len())+1 |
=rand(CNames.len())+1 |
|
3 |
return PNames(A2),CNames(B2) |
|
这个子程序从PNames和CNames分别随机取出1个成员返回。其中PName和CNames是需要传入的网格参数:
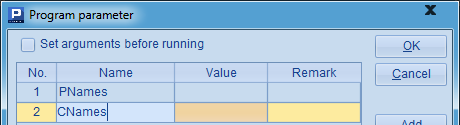
在主程序中调用的情况如下:
|
|
A |
B |
|
1 |
=create(Product,Customer) |
|
|
2 |
=5.(call("createID.dfx ",2)) |
=10.(call("createID.dfx ",rand(3)+3)) |
|
3 |
for 100 |
=call("findNames.dfx",A2,B2) |
|
4 |
|
>A1.insert(0,B3(1),B3(2)) |
先在A2和B2中调用前面的网格createID.dfx,生成产品名称序列和客户名序列。再在A3中循环,B3中调用网格findNames.dfx,将A2和B2作为参数传入。注意,调用call时使用多个参数时,这些参数值将依次设入dfx的各个参数中,与dfx参数列表中的参数名无关。也就是说,在这里只根据参数的顺序,A2的值赋值给PNames,B2的值赋给CNames。当所调用的程序用return语句返回多个结果时,不必像子程序中的return语句一样用结果构成序列,只需将结果用逗号分隔,数据返回时会自动构成序列。在B3中可以查看最后一次调用网格时,返回的结果如下:
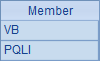
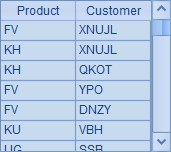
上面这个主网格的效果,是随机生成100条测试数据插入A1中的序表,记录由产品名与客户名随机构成。执行后,A1中的结果如下:
同样,所调用的网格程序中并不要求必须返回结果,如文件D:\files\addRecord.dfx如下:
|
|
A |
B |
|
1 |
/add a record |
|
|
2 |
=Table.len()+1 |
=(rand(1000)+1)*100 |
|
3 |
>Table.insert(0,A2,PNAME,CNAME,B2) |
|
网格中使用了三个参数,需要分别传入产品名PNAME、客户名CNAME以及使用的序表Table:

在主网格中,调用如下:
|
|
A |
B |
|
1 |
=create(OID,Product,Customer,Amount) |
|
|
2 |
=5.(call("createID.dfx ",2)) |
=10.(call("createID.dfx ",rand(3)+3)) |
|
3 |
for 100 |
=call("findNames.dfx",A2,B2) |
|
4 |
|
>call("addRecord.dfx",B3(1),B3(2),A1) |
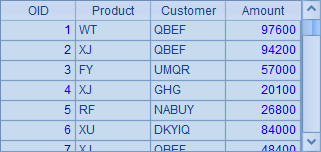
其中B4中调用了addRecord.dfx,在A1的序表中插入随机记录。执行后,A1的序表中随机生成测试数据如下:
通过跨网格调用,可以使得主网格中的代码更为简洁,使调用网格中的代码得以复用。同时,也可以将一些需要加密的算法放置在单独的网格中,在其它代码中调用。